

1. Aptos 인센티브 테스트넷 단계별 로드맵
최근 많은 관심을 받는 앱토스(Aptos) 블록체인의 세 번째 인센티브 테스트넷(Incentivized Testnet)이 지난 8월 30일을 시작으로 9월 9일 성공적으로 종료되었습니다. 메인넷 론칭 전 마지막 인센티브 테스트넷이었던 만큼 세계적으로 많은 관심과 참여가 이뤄졌습니다.

Aptos 인센티브 테스트넷은 이번 3단계 라운드를 포함하여 총 4개의 라운드로 테스트넷이 진행됩니다. 각 라운드의 목표는 아래와 같습니다:
- AIT-1 : 유효성 검사기 노드를 시작하여 실행하고 문제점을 찾아 코드를 개선하는 것을 목표로 합니다.
- AIT-2 : 테스트넷에 여러 버전의 바이너리(Binary) 업데이트를 진행하면서, 밸리데이터 노드에 배포하여 테스트하였습니다. 또한, 각 노드의 퍼포먼스에 따라 평판(Reputation)을 분석하는 알고리즘을 개선합니다.
- AIT-3 : 메인넷 출시 전 마지막 인센티브로 전반적인 시나리오에 대한 테스트가 진행되었습니다. 거버넌스(Governance)와 거버넌스의 역할에 중점을 두고 테스트가 진행되었고, 네트워크 스트레스 테스트를 진행하면서 여러 상황을 만들고 밸리데이터와 Aptos 팀이 이에 대응하는 것에 초점을 두었습니다.
- AIT-4 : 2022년 4분기 진행 예정
2. 밸리데이터의 높은 진입장벽
다른 고성능의 Layer 1 블록체인과 마찬가지로, Aptos 테스트넷의 밸리데이터 노드 또한 높은 스펙이 요구되었습니다. AIT-3에서 권장된 최소한의 하드웨어 리소스는 아래와 같습니다:
CPU :
- 8 cores, 16 threads
- 2.8GHz, or faster
- Intel Xeon Skylake or newer
Memory : 32GB
Storage : 1T SSD with at least 40K IOPS and 200MiB/s bandwidth.
Networking bandwidth : 1Gbps
일반적인 네트워크 상황에서는 많은 CPU 로드와 메모리, 스토리지가 요구되지 않습니다. 하지만 위 테스트넷의 목표를 상기해 보면, 테스트넷에서는 네트워크의 과부하 상황 혹은 Stale 노드와 지리적 위치에 따른 블록 동기화(Synchronization) 이슈 등 여러 상황을 염두에 두고 테스트가 진행되어야 하므로 이를 위한 최대한의 하드웨어 리소스를 필요로 하였습니다.
3. 지속적인 커뮤니티 관찰을 통한 밸리데이터 참여 준비
AIT-3에 참여하기 전, AIT-2가 진행되는 동안 Aptos 디스코드를 통해 참가자들의 진행 상황을 모니터링했습니다. AIT-2 시작 당시 모든 밸리데이터 참여자들은 같은 선상에서 출발하였지만, 초기 참여자의 오퍼레이팅(Operating) 역량에 따라 Voting과 Proposal의 수가 크게 차이가 난다는 점을 발견하였습니다.
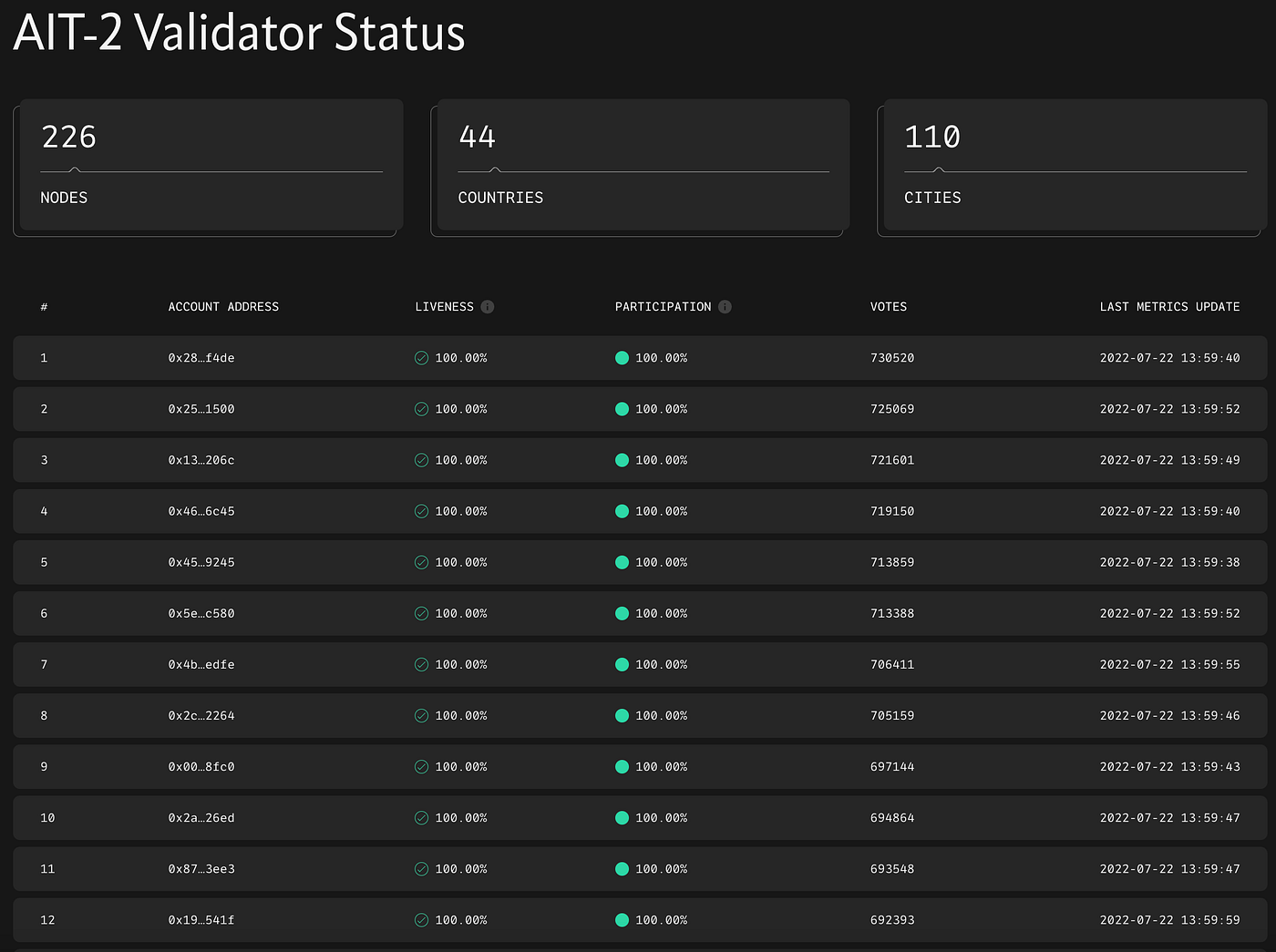
Aptos 팀에서 제공하는 익스플로러(Explorer)와 리더 보드(Leader Board)를 통해서 초기 Voting을 받지 못한 노드는 시간이 지남에 따라 Aptos의 평판(Reputation) 알고리즘으로부터 점진적으로 선출되기 힘들어지는 패턴을 파악할 수 있었습니다.

Aptos 팀에서는 테스트넷인 만큼 여러 극한의 네트워크 상황을 인위적으로 만들기도 하고, 돌발적인 시나리오를 연출하여 디스코드를 통해 어나운스하였습니다. 이 당시 팀의 어나운스와 가이드라인에 발맞춰 빠르게 대응한 오퍼레이터는 높은 Voting을 받음으로써 Reputation 알고리즘에 의해 높은 신뢰도 쌓기가 가능했습니다.
이처럼 커뮤니티를 지속해서 관찰하는 것만으로도 많은 간접 경험을 할 수 있었는데, 단순히 팀의 가이드라인에 따라 오퍼레이팅 하는 것만이 중요한 것이 아니었습니다. 안정적인 노드 오퍼레이팅을 위해 Aptos 팀 그리고 오퍼레이터들과 지속적인 커뮤니케이션이 필요했으며 데이터를 기반으로 한 적절한 판단이 요구되었습니다.
4. 모니터링과 대응의 중요성
앞서 Aptos 오퍼레이터 커뮤니티를 관찰하면서 가장 크게 느꼈던 점은 데이터를 기반으로 ‘빠른 판단’을 내리고 ‘즉각적인 대응’을 하는 것이었습니다. 테스트넷은 메인넷 출시 전 여러 시나리오와 기능들을 테스트하는 것이 목표인 만큼 기능적 결함을 경험하고 팀에서는 이를 개선하기 위한 업데이트를 자주 진행하였습니다.
따라서 24시간 긴급하게 대응할 수 있는 환경에서 커뮤니티를 확인해야 하는 것이 필수적으로 요구되었습니다. 뿐만 아니라, 밸리데이터 노드의 컴퓨팅 리소스가 가용 영역을 초과하지 않는지 혹은 지표가 평시 패턴과 다른 모습을 나타내지는 않는지 세심하게 모니터링할 필요가 있었습니다. 때문에 이러한 주요 지표들을 놓치지 않기 위해 밸리데이터 노드의 지표 변화 감지를 위한 인프라를 구축하였습니다.
5. 빠른 대응을 위한 인프라 구축
VPS(Virtual Private Server) 제공 서비스로 Vultr, Contabo, GCP(Google Cloud Platform), AWS(Amazon Web Service), Azure 등 다양한 서비스들이 있지만, Aptos 팀에서는 노드의 안정성을 위해서 AWS와 GCP를 권고하고 이에 대한 인스턴스 타입을 제시하였습니다. 저 또한, 안정성과 AWS 생태계 내의 Auto Scaling을 포함하여 다양한 편의 기능을 활용하기 위해 AWS의 EC2 서비스를 선택했습니다.
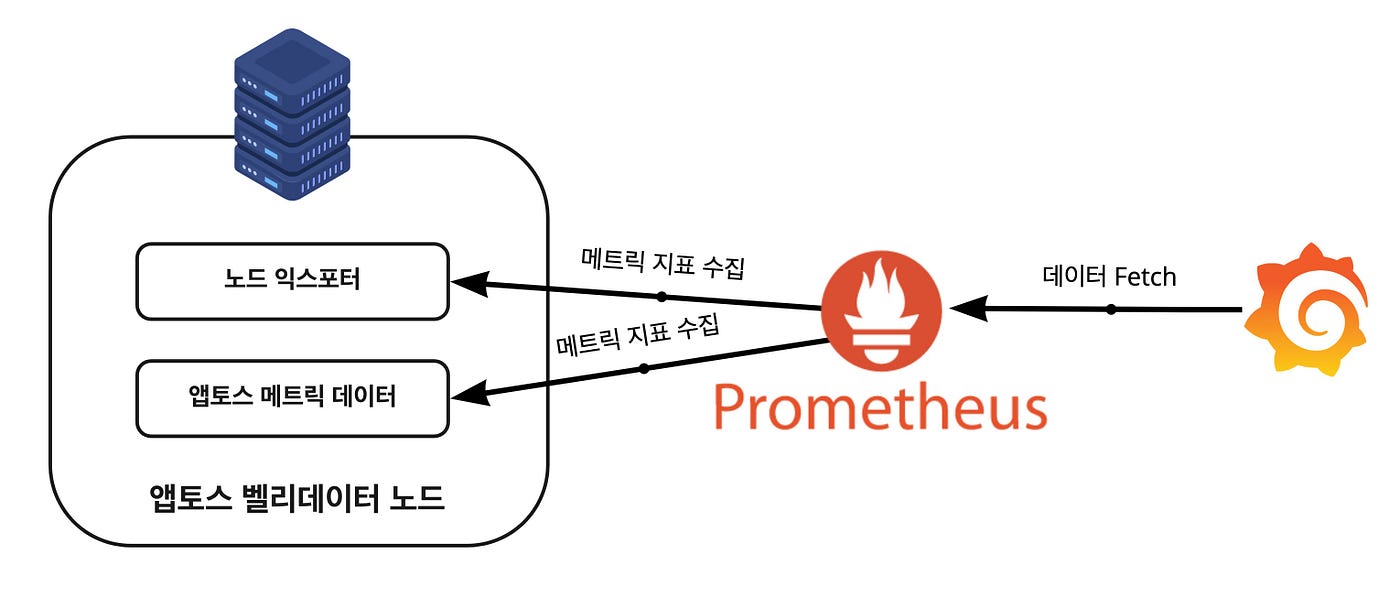
그 외 각종 지표를 좀 더 정밀하게 모니터링하면서 시각화를 통해 쉽게 분석하기 위해 Prometheus를 사용하여 시스템 및 Aptos의 메트릭(Metric) 데이터를 수집하고 Grafana를 통해 수집된 데이터를 시각화하고 모니터링했습니다.
6. 안정적인 노드 운영을 위한 업데이트
AIT3는 메인넷 이전의 마지막 테스트넷인 만큼 Aptos 팀에서도 길지 않은 테스트넷 기간 동안 네트워크 개선을 위해 많은 시나리오 테스트를 진행했습니다.
테스트 기간 중 개선할 수 있는 Bug Fix 혹은 Feature에 대한 업데이트 어나운스가 잦았습니다. 하지만 대부분 UST(Coordinated Universal Time) 시간대에 업데이트 어나운스가 되었고, 제가 주로 대응할 수 있는 시간대는 이와 9시간이 차이 나는 KST(Korea Standard Time)이었기 때문에 즉각적인 대응이 쉽지 않았습니다. 이에 집중하기 위해 생활패턴의 변화를 주고, 알람을 통해 즉각적인 대응할 수 있도록 했습니다.
테스트넷 기간 동안 빠르게 어나운스 되는 업데이트는 항상 완벽하지 않다는 점을 인지하고 있었습니다. 대부분의 업데이트는 Emergency 레벨의 업데이트가 아니라면 어나운스가 나오는 즉시 반영하지 않았고 1~2시간의 간격을 두고 업데이트를 적용했습니다.
이러한 방식으로 오퍼레이터 커뮤니티를 통해 어떤 이슈를 조기에 발견했는지 혹은 업데이트된 바이너리에 대해 Aptos 팀에서 미처 발견하지 못한 이슈는 없었는지 확인을 한 뒤, 업데이트는 최대한 보수적으로 진행했습니다. 노드를 운영하는데 크리티컬(Critical) 한 이슈가 아니라면, Feature 혹은 Bug Fix을 해결하는 것보다 블록체인 네트워크 내의 피어(Peer)와 안정적으로 통신하도록 노드를 운영하는 것이 밸리데이터 오퍼레이터로서 가장 높은 우선순위라고 생각했습니다.
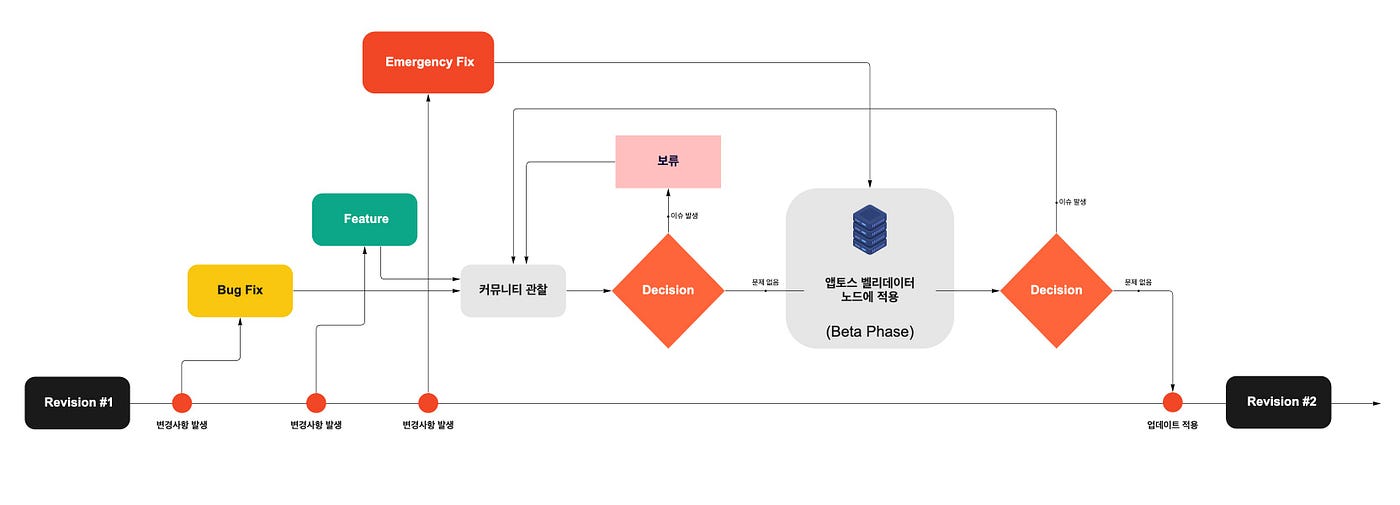
이러한 접근 방식 외로도 업데이트를 선제적으로 적용해보고 테스트할 수 있는 베타 단계 (Beta Phase)의 노드를 별도로 구축하여 이를 적극적으로 활용했습니다. 물론 Aptos 팀에서도 내부 테스트를 거친 뒤, 어나운스 하겠지만 앞서 언급한 것과 같이 노드의 안정성이 가장 중요하였기 때문입니다.
베타 단계의 노드에 업데이트를 적용해보고 1시간 동안 문제가 없었다면 대부분 메인 밸리데이터 노드에 적용했을 때 별다른 이슈가 없었기 때문에 이러한 배포 프로세스를 통해 안정적으로 노드를 운영할 수 있었습니다.
7. 예상치 못한 문제 방지를 위한 컴퓨팅 리소스 패턴과 로그 분석
발생할 수 있는 문제를 미리 선제적으로 예측하고 방지하는 것도 중요하지만, 예상치 못한 문제가 발생했을 때 사후 분석을 통해 향후 발생할 수 있는 문제를 인지하고 계획을 세우는 것 또한 안정적인 노드를 운영하기 위해 필요합니다.
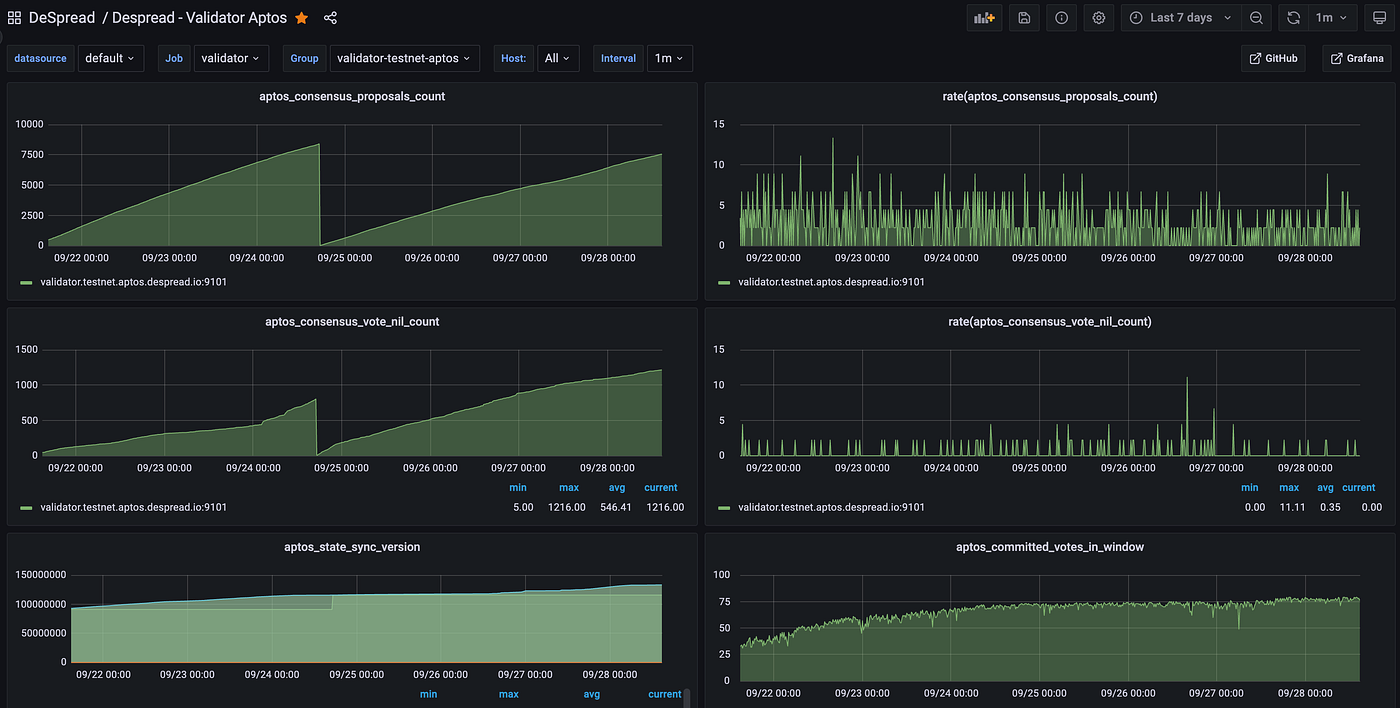
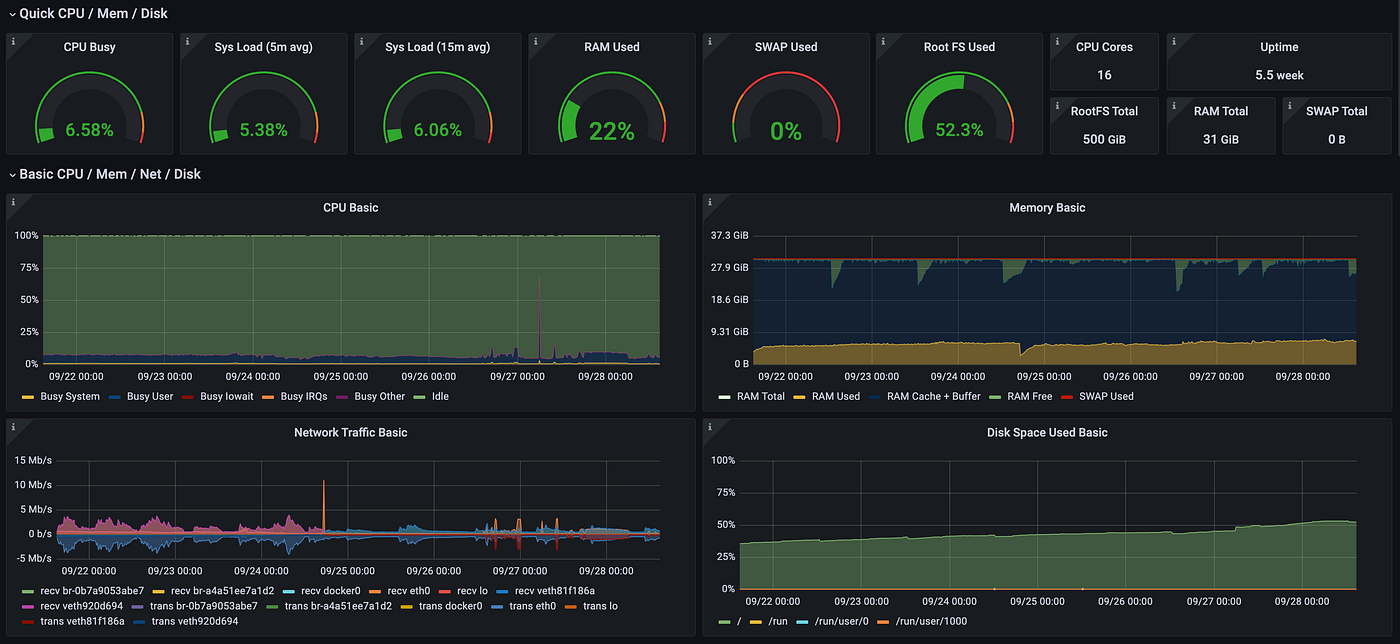
예상치 못한 문제 분석을 위해서는 컴퓨팅 리소스의 이상 징후 패턴과 노드의 Access Log와 Error Log를 주의 깊게 살펴보는 것이 가장 중요합니다. 컴퓨팅 리소스에 대한 패턴 분석은 Grafana를, 로그에 대한 분석은 Logstash, Elasticsearch, Kibana를 활용했습니다.
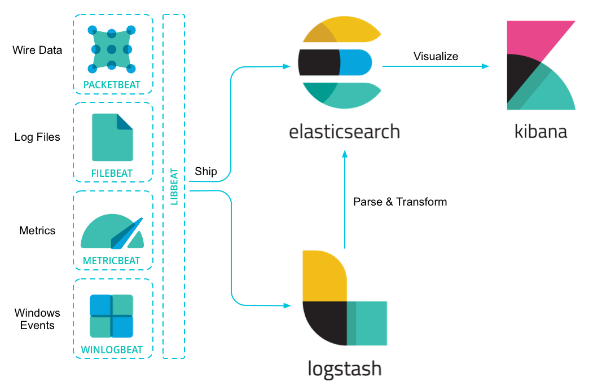
애플리케이션 영역의 지표는 문제가 발생할 경우 추적할 수 있어야 하기 때문에 단순히 시각화만 가능한 도구를 사용하는 것은 좋지 않겠다고 생각했습니다. 따라서, APM(Application Performance Management)을 통해 요청을 추적하고 Rich 한 분석을 할 수 있는 Elasticsearch를 채택했습니다.
Logstash를 통해 Aptos의 로그를 수집하고, 분석을 위해 적합한 형태의 구문으로 변환한 뒤 Elasticsearch에 로그를 적재하여 Kibana를 통해 분석했습니다. Elastic Stack 내에서 지원되는 기능들이 많고 향후 필요하다면 이러한 로그를 기반으로 머신러닝(Machine Learning)을 통해 문제 예측도 가능하게 됩니다.

Kibana가 제공하는 강력한 시각화 기능과 Elasticsearch의 조건 검색 기능을 활용하면, 문제가 되는 로그나 패턴을 쉽게 찾을 수 있기 때문에 문제를 추적하는 데 소요되는 시간을 획기적으로 줄일 수 있었습니다. Kibana를 선택한 또 다른 이유 중 하나로 시간의 경과에 따른 성능 패턴이나 이상치를 쉽게 확인할 수 있는 산포도(Scatter Plot)를 지원하기 때문입니다. 이를 통해 감이나 눈대중으로 성능을 확인하는 것이 아닌, 데이터를 기반으로 명확하게 성능을 측정하여 Throughput과 Latenecy 등 주요 성능의 지표 변화를 한눈에 파악할 수 있습니다.
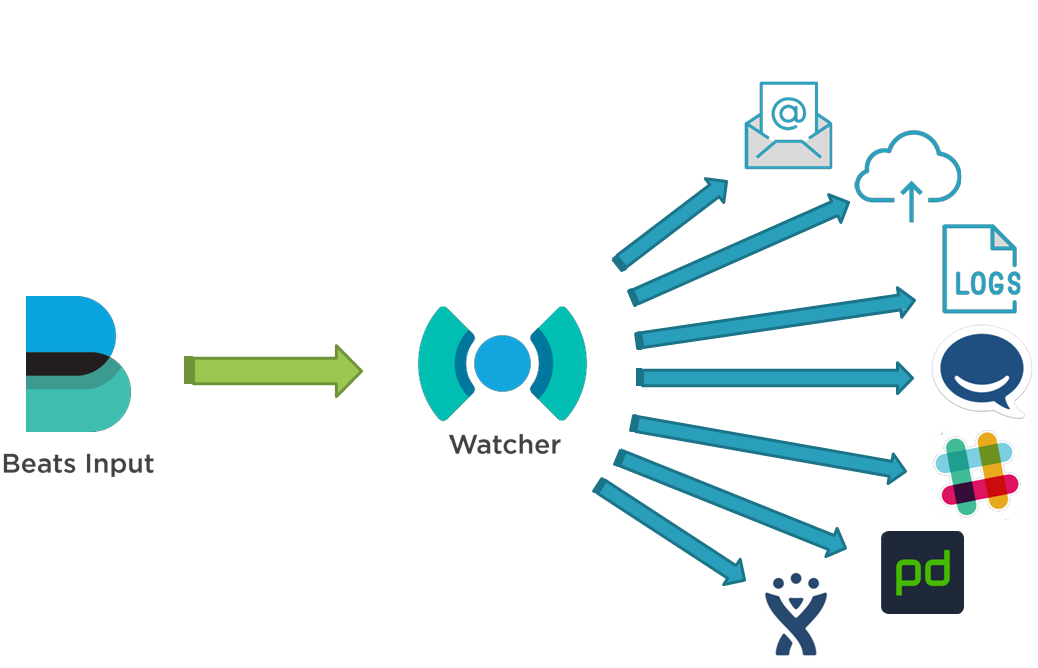
이 외에도, 와처(Watcher) 기능을 통한 배치(Batch) 작업이나 트리거(Trigger)를 작동시킬 수 있고, 리포트 메일이나 웹훅(Webhook)을 통해 Slack과 Telegram 같은 주로 사용되는 메신저와도 연동을 할 수 있습니다. 향후에 필요하다면 캔버스(Canvas)나 대시보드(Dashboard)를 통해 외부에 필요한 데이터를 쉽게 공개할 수 있으니 이러한 기능만으로도 Elasticsearch를 채택하기에 충분했습니다.
다만, 사용하기 편한 만큼 비용이 높다는 문제가 있지만 장기간 보관되는 로그는 아니기 때문에 적절한 보유 기간(Retention)을 설정하면 Elasticsearch를 활용해서 적은 비용으로도 높은 효율을 낼 수 있습니다. JVM(Java Virtual Machine) 위에서 Lucene을 기반으로 동작하는 Elasticsearch만의 고유한 문법과 정책으로 러닝 커브(Learning Curve) 또한 존재하지만, 앞서 언급한 Elastic Stack 내의 강력한 기능들만으로도 이를 충분히 상쇄할 수 있다고 생각합니다.
8. 마치며
이번 Aptos의 인센티브 테스트넷 3는 디스프레드에서 밸리데이터로서 처음으로 참여한 블록체인 프로젝트였습니다. 밸리데이터로서 블록체인 생태계에 처음 참여한 만큼 어려운 점도 있었지만, 상황에 맞추어 인프라를 빠르게 구축하고 데이터 기반으로 하는 업데이트와 즉각적인 대응을 통해 안정적으로 노드 운영을 할 수 있었습니다.
그 결과, 288개의 노드 참여자 중에서 3위에 해당하는 스코어를 획득할 수 있었습니다. 이러한 결과를 바탕으로 Aptos 팀으로부터 메인넷(Mainnet)의 밸리데이터 노드로의 참여 제안을 받아, Aptos 생태계에 밸리데이터 노드 오퍼레이터(Operator)로서 참여하는 기회로 이어졌습니다.
본 아티글을 통해 밸리데이터 노드 오퍼레이터를 준비했던 과정과 안정적인 노드 오퍼레이팅을 위해 어떠한 방식으로 접근했는지에 관해서 기술하였으며, 다른 밸리데이터 분들께도 도움 되기를 희망합니다. 앞으로도 멀티 체인 생태계의 빌더로서 커뮤니티에 참여하여 함께 성장해 나아가길 기대하면서 본 아티클을 마칩니다.