
Aptos Incentivized Testnet 3 Validator Participation Review
All about Aptos Incentivized Testnet 3

1. Aptos Incentivized Testnet Phased Roadmap
The third incentivized testnet of the Aptos blockchain, which has recently attracted keen attention, started on August 30 and ended successfully on September 9. Since it was the last incentive testnet before the launch of the mainnet, there was a lot of interest and active participation worldwide.

The Aptos Incentivized Testnet will run for a total of four rounds, including the third round. The goals of each round are as follows:
- AIT-1: It aims to get the validator node up and running, finding problems and improving the code.
- AIT-2: While binary versions of several versions on the testnet were updated, they were tested by distributing them to the validator node. In addition, it improves the algorithm that analyzes the reputation according to the performance of each node.
- AIT-3: The overall scenario was tested through the last incentive before the mainnet launch. Testing focused on governance and its role, and involved different situations being created during network stress testing and the validators and Aptos team forming a response to these.
- AIT-4: It is scheduled to be conducted in the fourth quarter of 2022.
2. High barriers to entry for validators
Like other high-performance Layer-1 blockchains, the validator nodes of the Aptos testnet also required high specifications. The recommended minimum specifications of hardware resources for AIT-3 are as follows:
CPU :
- 8 cores, 16 threads
- 2.8GHz, or faster
- Intel Xeon Skylake or newer
Memory : 32GB
Storage : 1T SSD with at least 40K IOPS and 200MiB/s bandwidth.
Networking bandwidth : 1Gbps
Under normal network conditions, a lot of CPU load, memory, and storage are not required. However, recalling the goal of the testnet above, the testnet warrants the maximum specifications of hardware resources because the test had to be conducted with various scenarios in mind, such as network overload or block synchronization issues according to stale nodes and geographic locations.
3. Preparation to engage validators through ongoing community observation
Prior to participating in the AIT-3 phase, participants’ progress was monitored via Aptos Discord during the AIT-2 phase. At the beginning of the AIT-2 phase, all validator participants started on a level playing field, but it was found that the number of voting and proposals was significantly different depending on the operating ability of the initial participant.
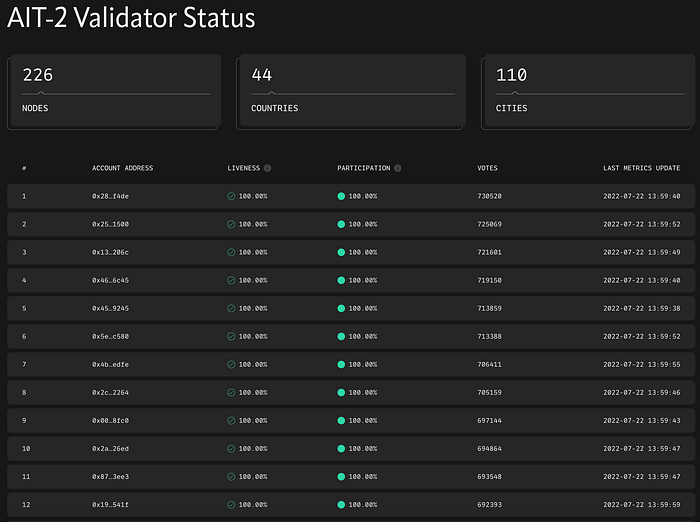
Through Explorer and Leader Board provided by the Aptos team, nodes that did not receive initial voting were able to identify a pattern where it becomes gradually difficult to be elected from the Aptos’ reputation algorithm over time.
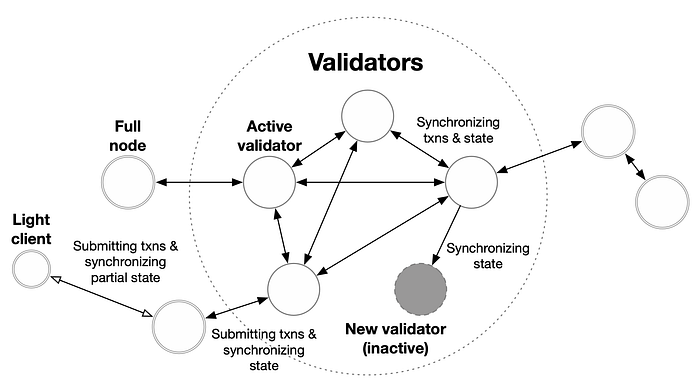
Given that it is a testnet, the Aptos team artificially created various extreme network conditions, created unexpected scenarios, and announced them through Discord. Then operators who responded swiftly in alignment with the announcements and guidelines of the team at that time received high voting, thereby enabling them to build high reliability with the reputation algorithm.
This continuous observation of the community provided a lot of indirect experience, but it wasn’t primarily about operating according to the team’s guidelines. For stable node operations, constant communication with the Aptos team and operators as well as optimal decisions based on data were required.
4. Importance of monitoring and response
The biggest thing that stood out while observing the Aptos operator community is the ability to make ‘swift decisions’ and ‘immediate responses’ based on data. Given that the testnet aims to test various scenarios and functions before the mainnet launch, functional flaws could be experienced first-hand, and the team frequently could make updates to improve them.
Therefore, it was imperative to check the community in an environment capable of an urgent response at all times. In addition, it was mandatory to carefully monitor whether the computing resources of the validator nodes were not exceeding the available zone or that the metrics were not showing any deviations from normal patterns. Therefore, in order not to overlook these key indicators, we have built an infrastructure for detecting indicator changes in the validator node.
5. Building infrastructure for quick response
Although there are various services such as Vultr, Contabo, Google Cloud Platform (GCP), AWS (Amazon Web Service), and Azure that are provided by a VPS (Virtual Private Server), the Aptos team recommends AWS and GCP for node stability, and proposes the instance type in this regard. Personally, we also chose AWS’s EC2 service to capitalize on its reliability and various convenience features including auto scaling within the AWS ecosystem.

For an easy analysis with the above visualization while monitoring various other indicators more precisely, metric data of the system and Aptos were collected using Prometheus, with the collected data being visualized and monitored through Grafana.
6. Updates for stable node operations
Given that the AIT3 phase is the last testnet before the mainnet, the Aptos team also conducted many scenario tests to improve the network during the short testnet period.
During the test period, there were frequent update announcements about bug fixes or features that could be improved. However, most of the update announcements were made in the UTC (Coordinated Universal Time) time zone, and my main response time was KST (Korea Standard Time), which is a 9-hour difference, so it was not easy for me to respond immediately. To stay on the ball, my lifestyle patterns had to be altered and an immediate response required setting an alarm.
We were well-aware that updates that are announced quickly during the testnet are not always perfect. Most of the updates were not reflected immediately after an announcement was released, unless it was an emergency-level update, while updates were applied at intervals of 1 to 2 hours.
In this way, after checking which issues were discovered in advance through the operator community or whether there were any issues that the Aptos team had not yet detected as to the updated binary, the update was carried out as conservatively as possible. If it is not a critical issue to operating a node, we thought that operating a node to communicate stably with peers in the blockchain network was the highest priority as a validator operator, instead of solving a feature or fixing a bug.
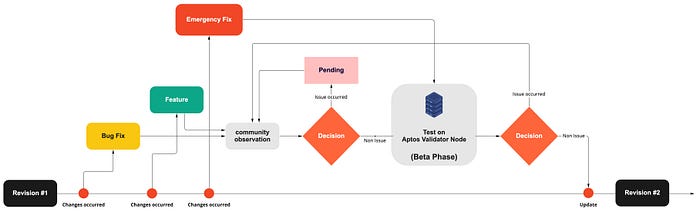
Besides this approach, we actively capitalized on this by building a separate node in the beta phase where we can proactively apply and test updates. For sure, the Aptos team will announce this after internal testing, but as mentioned earlier, the stability of the node was the most important factor.
If the update was applied to the node in the beta stage without any problems for an hour, most of the time, there were no issues when applying it to the main validator node, so the node could be operated stably through this deployment process.
7. Compute resource patterns and log analysis to avoid unexpected problems
Although it is important to predict and prevent problems that may occur in advance, in the case of unexpected problems, recognizing and planning future problems through post-analysis is also required to operate a stable node.
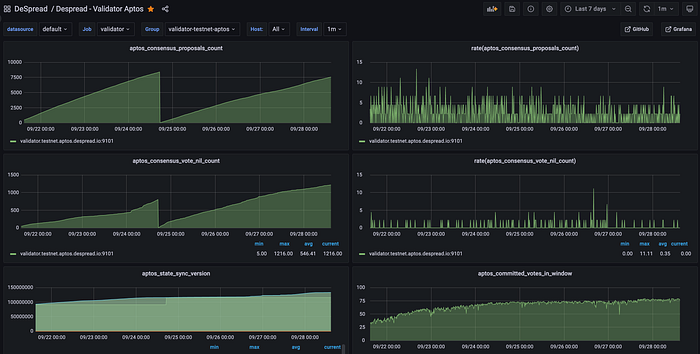
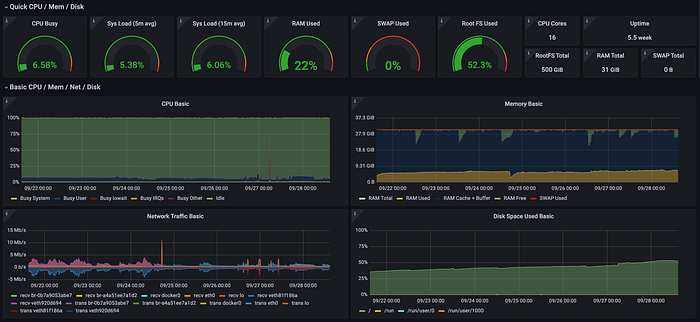
In order to analyze unexpected problems, it is most important to carefully look at the anomaly patterns of the computing resources and the access logs and error logs of the nodes. Grafana was used for pattern analysis on computing resources, and Logstash, Elasticsearch, and Kibana were used for log analysis.
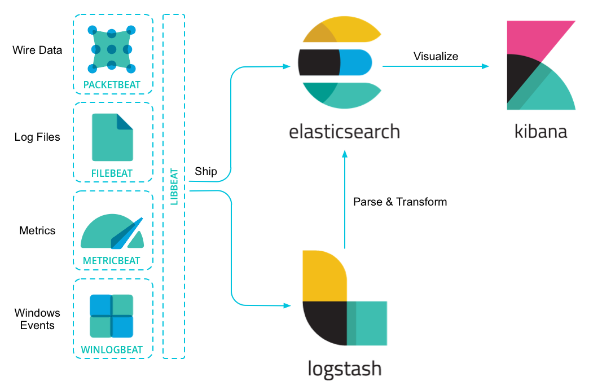
Since metrics in the application domain need to be able to be tracked in the event of issues occurring, it would be a bad idea to use a tool that could only be visualized. Therefore, we adopted Elasticsearch, which can track requests and perform rich analysis through APM (application performance management).
Aptos logs were collected through Logstash and converted into a suitable format for analysis, after which the logs were loaded into Elasticsearch and analyzed through Kibana. There are many functions supported within the “Elastic Stack”, and if required going forward, it is also possible to predict problems through the use of machine learning based on these logs.

By leveraging the robust visualization capabilities provided by Kibana and the conditional search capabilities of Elasticsearch, the amount of time spent tracking down problems was able to be significantly reduced because it was easy to find problematic logs or patterns. Another reason to choose Kibana is because it supports a scatter plot that makes it easy to spot performance patterns or outliers over time. Through this, it is feasible to clearly measure performance based on data, so that changes in key performance indicators such as throughput and latency can be learned at a glance, as opposed to checking the performance by feeling or eyeballing it.
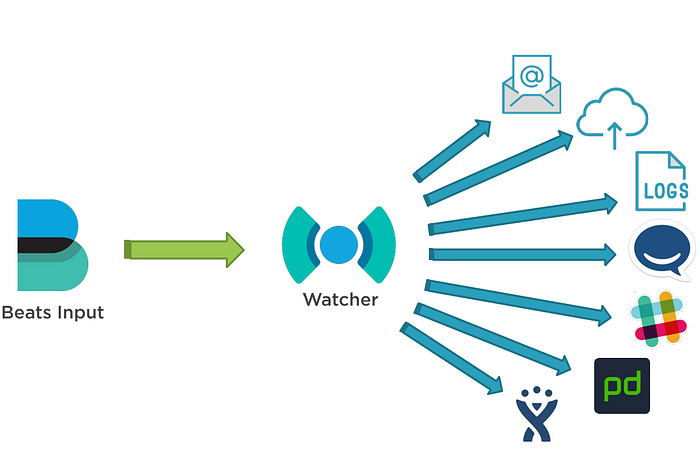
In addition to this, batch tasks or triggers can be activated through the watcher function, and can also be linked with commonly used messengers, such as Slack and Telegram, through report mail or webhook. If required in the future, it was easy to publicize required data externally through Canvas or Dashboard, so these functions alone were sufficient to adopt Elasticsearch.
However, there is the problem of incurring high costs despite being easy to use, but since the logs are not stored for a long time, by setting an appropriate retention period, Elasticsearch can be used to achieve high efficiency at a low cost. Although there is a learning curve concerning the exclusive syntax and policy of Elasticsearch that operates on the Java Virtual Machine (JVM) based on Lucene, I think that the robust functions above within the “Elastic Stack” alone can sufficiently offset for this.
8. Conclusion
This Aptos Incentivized Testnet 3 is the first blockchain project that I participated in as a validator on DeSpread. As a validator, it was difficult to participate in the blockchain ecosystem for the first time, but the infrastructure was able to be quickly built according to the situation and the node was operated stably through data-based updates and immediate responses.
As a result, out of 288 node participants, the Aptos team was able to obtain a score in 3rd place. Based on these results, we received an offer to participate as a validator node on the mainnet, along with an opportunity to participate as a validator node operator in the Aptos ecosystem.
This article has described the preparation process of a validator node operator and how we formulated our approach for stable node operations, in the hope that it will be helpful to other validators as well. This wraps up the article as we look forward to continue growing together and participating in the community as builders of the multichain ecosystem.
Devgang.eth Twitter: https://twitter.com/devgang_eth