

1. 들어가며
디스프레드는 약 5년여간 많은 웹3 기업들과 협업해오면서 어떻게 이들에게 더 많은 도움을 주고 시장에 기여를 할 수 있을지 고민했습니다. 이에 따라 지난해부터 디스프레드 랩스(사내 내부 개발 팀)을 본격적으로 꾸리기 시작했으며 최근엔 팀 규모가 3배 가까이 확대되었습니다.
디스프레드 랩스는 이러한 성장에 발맞추어, 효율적인 개발을 위해 다양한 “현대화” 작업을 진행하고 있습니다. 기존 프로젝트는 Kubernetes로의 이전 작업을 진행 중이며, 새로운 프로젝트는 모두 Kubernetes를 기반으로 개발하고 있습니다. 이 과정에서 많은 시행착오를 겪었고, 새로운 지식도 습득하게 되었습니다.
이번 글에서는 디스프레드 랩스가 Kubernetes를 도입하면서 어떤 솔루션을 선택하고 적용했는지, 그 과정과 이유를 소개하고자 합니다.
2. 기존 CI/CD 전략

위 그림은 Kubernetes를 도입하기 전의 기존 CI/CD 전략을 도식화한 것입니다.
기존에는 AWS 콘솔로 인프라를 설정하고 관리하다 보니 이용하는 서비스 종류가 많아 관리가 어렵고 효율적인 관리가 어려웠습니다.
또한, 매번 Branch를 병합한 후 빌드/배포 과정에서의 번거로움이 많으며 롤링 업데이트, 블루/그린 배포, 카나리아 배포 등 다양한 배포 전략을 구현하기가 까다로웠습니다. 특히, 별도의 스크립트를 작성하거나 툴링을 사용하지 않고 Production 환경에서의 무중단 배포를 하기가 어려웠습니다.
2.1. 기존 인프라 관리의 어려움
디스프레드 랩스는 초기에 프로덕트를 개발한 후 MVP를 기반으로 빠르게 PMF(Product Market Fit)를 찾는 것에 집중해야 했기 때문에, 인프라 혹은 툴링에 대한 관리 포인트를 줄이는 것이 가장 중요했습니다. 따라서 아래의 기준을 근거로 현재 파편화된 인프라를 어떻게 중앙 집중화시키고, 효율적으로 관리할 수 있을지에 대해서 고민하였습니다.
- 인프라에 대한 관리를 최소화 해야 한다
- 팀원들의 기존 개발 환경과 매끄럽게 연결될 수 있어야 한다
- 확장성이 좋아야 한다
- 모니터링과 로깅을 쉽게 할 수 있어야 한다
- 보일러 플레이트(Boilerplate)를 줄일 수 있어야 한다
2.2. 쿠버네티스 도입 필요성을 느끼다
2.2.1. 세부 도메인으로 세분화
초기 디스프레드 랩스에서는 상황에 따라 필요한 툴링이나 밸리데이터 운영에만 초점을 맞추고 운용되었습니다. 그러다 보니 각 도메인의 기능이 세분화 되고 크기가 커짐에 따라 의존성 문제와 관리와 개발 비용을 상승시키는 문제가 대두되기 시작했습니다.
각 도메인을 분리해서 개발 비용을 낮추고 기존 모놀리식 구조에서 제공하던 데이터의 유기적인 흐름을 모두 만족시켜야 하는 새로운 요구사항이 생겼습니다.
2.2.2. 실시간 이벤트 수집
디스프레드 랩스에서는 커뮤니티에서 논의되는 이슈나 온체인 정보를 분석해서 리서치에 활용하거나 저희 온보딩 플랫폼의 이벤트에 참여한 사용자에게 맞춤 컨텐츠를 제공하고 있습니다.
이를 위해서는 이벤트와 로그를 수집하고 데이터 분석을 통해 사용자의 상황을 분석할 수 있어야 합니다. 또한 각 도메인에서 발생하는 데이터들이 유기적으로 연결되어 서로 다른 도메인에서 이를 활용할 수 있어야 합니다.
2.2.3. 마이크로 서비스에 대한 환경 지원
각 서비스마다의 특성과 상황에 따라 사용하는 언어와 프레임워크가 달랐기 때문에 기존의 모놀리식한 인프라 환경에서는 빠르게 확장하기가 어려웠습니다. 따라서, Kubernetes 같은 scalable한 솔루션을 이용하여 마이크로 서비스 마다 다른 환경을 빠르게 배포하고 테스트 해볼 수 있는 환경 구성이 필요해졌습니다.
개발 조직 규모가 커짐에 따라 위와 같은 새로운 요구사항이 생겨났습니다. 저희 디스프레드 랩스는 기존의 모놀리식한 구조에서 벗어나 유연한 환경에 대응이 가능한 인프라 환경과 각기 다른 도메인 서비스 분리했기 때문에 업계의 표준이라고 불릴 만큼 레퍼런스가 많고 안정적인 서비스가 입증된 Kubernetes를 도입했습니다.
3. 쿠버네티스 도입
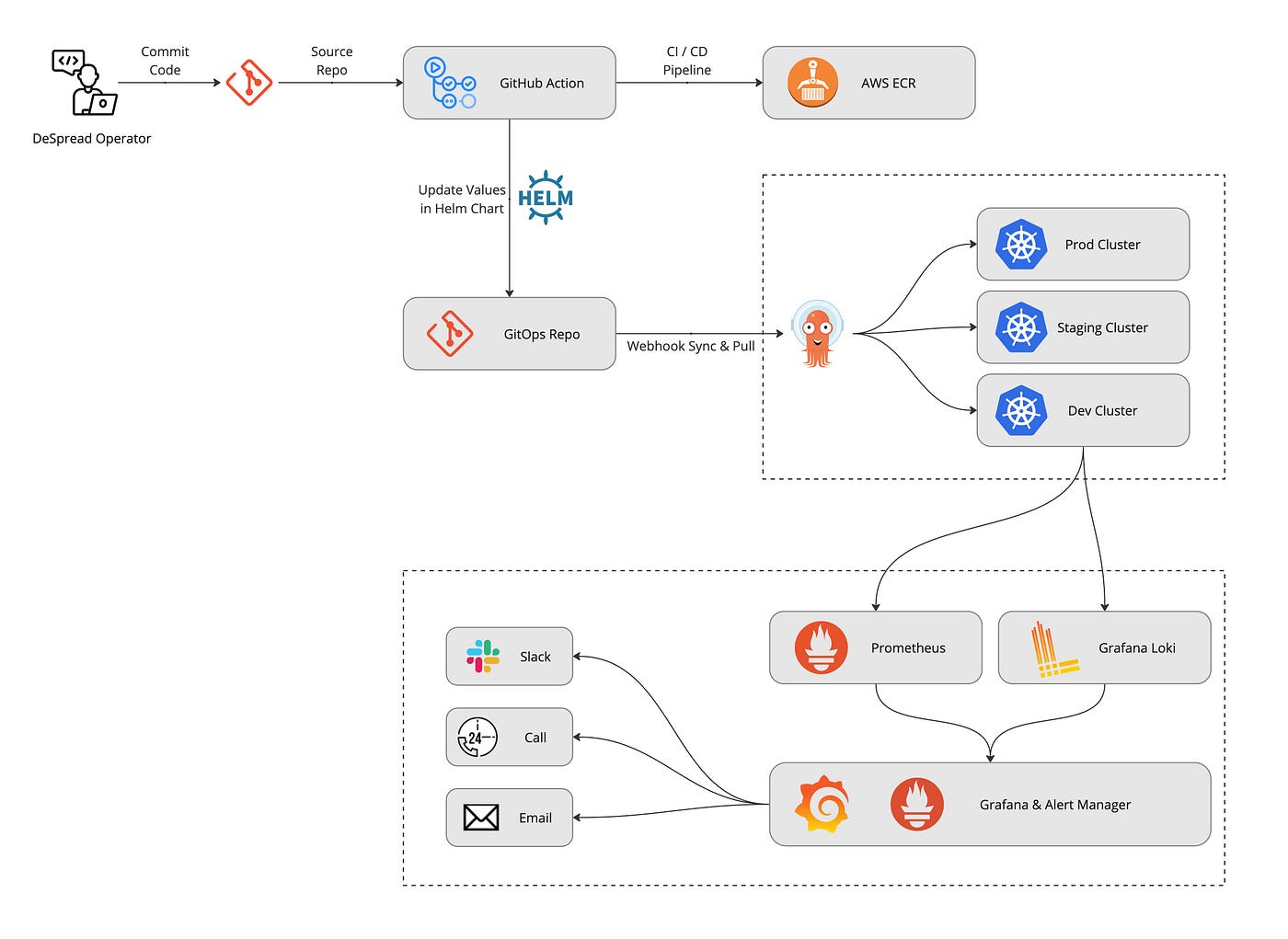
위 이미지는 쿠버네티스를 도입한 이후에 개선된 현재의 아키텍처입니다. 쿠버네티스는 Production, Staging, Dev 환경으로 3가지의 클러스터로 나누어 개발 환경을 구축했습니다.
그렇다면 CI/CD는 어떠한 과정으로 진행되는지 살펴보겠습니다.
3.1. CI(Continuous Integration)

CI는 지속적으로 품질을 유지하면서 코드를 통합한다는 개념입니다. 디스프레드 랩스에서는 프로젝트의 GitHub 레포지토리에서 코드 커밋을 하면 별도의 작업없이, GitHub Action을 통해 CI를 자동화 하였습니다.
개발 환경에서는 코드 커밋, Staging 환경과 Prod 환경에서는 PR(Pull Request)이 Merge되면 GitHub Action이 작동됩니다. GitHub Action에서는 각 프로젝트에 맞게 설정된 Docker 설정 파일을 통해 Docker 이미지를 빌드합니다. 정상적으로 빌드된 Docker 이미지는 디스프레드 랩스의 AWS ECR(Elastic Container Registry)의 private 레포지토리에 업로드 하게 됩니다.
프로젝트의 개발자 혹은 이해 관계자는 별도의 작업 없이도 코드 변경 작업을 하면 자동으로 빌드 및 배포를 실행할 수 있게 되므로 작업의 생산성을 높일 수 있습니다.
3.2. CD (Continuous Delivery & Deployment)
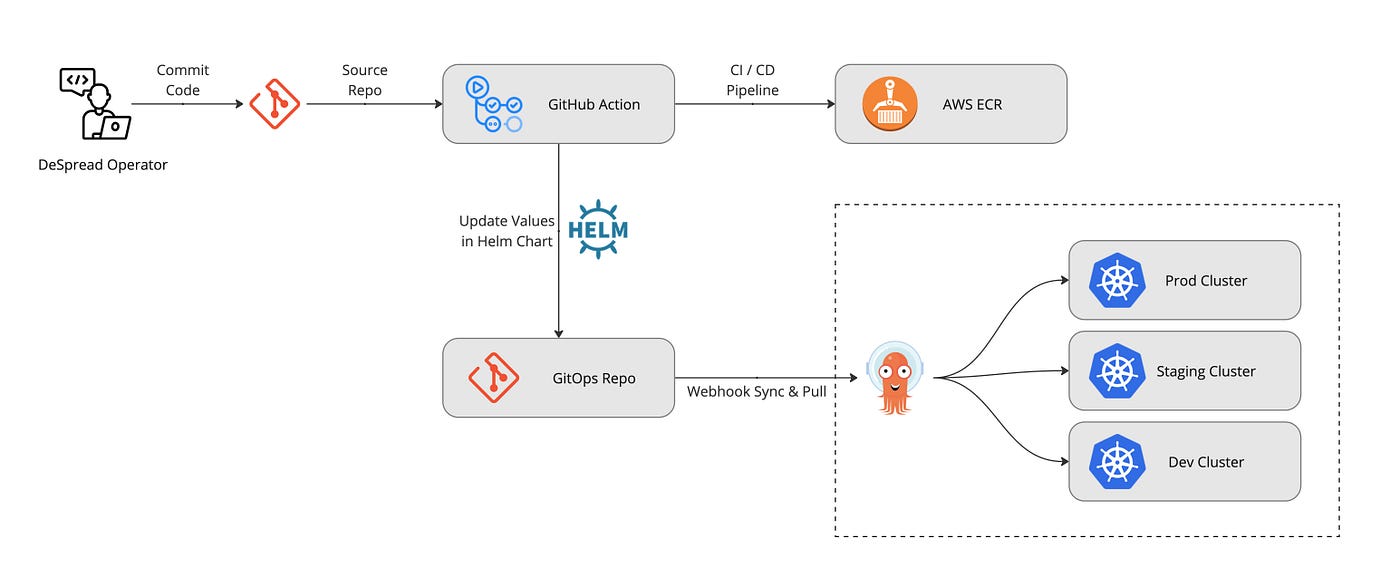
위 CI 과정에서 트리거된 GitHub Action 작업에서 최종적으로 CD를 위한 작업을 진행합니다. 새롭게 구축된 쿠버네티스는 Helm Chart를 기반으로 App of Apps 패턴에 따라 구현되어 있습니다.
Production, Staging, Develop 환경별로 모두 분리되어 있으며, Helm Chart로 Yaml파일들을 프로젝트 소스코드와 같이 관리하고 브랜치 운용절차에 맞게 코드를 Merge하면 위 과정을 통해 자동으로 통합되고 브랜치에 맞는 Kubernetes 클러스터의 Pod에 배포됩니다. 이 모든 과정은 ArgoCD를 통해 진행되며 작업자는 실시간으로 확인할 수 있습니다.
장애 상황 발생시 GitHub Repository에서 긴급하게 Helm Chart의 설정 파일을 변경할 필요 없이 ArgoCD를 통해 롤백을 하거나 설정 변경도 가능하므로 작업자는 이전보다 수월하게 대응할 수 있습니다.
또한, Service와 Ingress의 annotation 설정에 따라 ALB(Application Load Balancer)의 자동 생성과 더불어 Route53 서브 도메인 설정과 ACM의 인증서가 ALB로 자동으로 연동됩니다. 이제 개발자는 그저 코드를 수정하고 Merge만 한다면 배포까지 자동화 되어 진행됩니다.
지금까지 Kubernetes를 도입하면서 개선된 CI/CD 과정에 대해서 전반적으로 설명드렸습니다. 그렇다면 이 과정에서 어떠한 기술을 사용했는지에 대해서 주요한 기술 몇 가지를 통해 구체적으로 알아보도록 하겠습니다.
3.3. Helm Chart
IaC로 쿠버네티스 환경을 구축하기 위해서는 수많은 Yaml 환경 설정파일을 관리해야 합니다. Helm Chart는 쿠버네티스 애플리케이션의 배포와 관리를 간소화하고 자동화하기 위한 도구로, 복잡한 애플리케이션의 패키징, 버전 관리, 배포 자동화, 재사용 가능성, 의존성 관리, 표준화 등을 제공합니다.
이를 통해 다양한 환경에서 일관성 있는 배포를 유지하고, 특정 버전으로의 롤백 및 업그레이드가 용이하며, 커뮤니티에서 제공하는 다양한 차트를 활용하여 신속하게 애플리케이션을 배포할 수 있기 때문에 디스프레드 랩스에서는 패키지 매니징 툴로써 Helm Chart를 사용했습니다.
3.3.1. Helm 구조
helm 을 설치하고 helm create {chartname} 을 실행하면 아래와 같은 default 구조를 갖게 됩니다.
├─ Chart.yaml
├─ charts
├─ templates
│ ├─ NOTES.txt
│ ├─ _helpers.tpl
│ ├─ deployment.yaml
│ ├─ hpa.yaml
│ ├─ service.yaml
│ ├─ serviceaccount.yaml
│ └─ tests
│ └─ tests-connection.yaml
└─ values.yaml
위 Helm 구조에 대해서 간단하게 설명하자면 아래와 같습니다:
- Chart.yaml: 차트의 이름과 버전을 지정할 수 있습니다.
- Values.yaml: 사용자가 릴리즈 하려는 인스턴스에 대해 수정 가능한 설정을 포함합니다.
- Templates: values.yaml 파일에 선언된 변수를 이용해서 Kubernetes 매니페스트 파일을 생성하는 템플릿 파일이 존재합니다.
- Charts: 의존성 있는 차트 패키지들 설치, requirement.yaml 파일에 의존성이 있는 차트를 명시할 경우, charts 폴더에 차트파일이 저장됩니다.
3.4. 유연한 배포 전략
디스프레드 랩스에서는 ArgoCD를 이용하여 GitOps 시스템을 구축하여 배포하는데 필요한 노력과 비용을 최소화하고 있습니다. 그렇다면 GitOps가 어떠한 개념인지, 코드를 어떠한 전략으로 관리하고 있는지 살펴보도록 하겠습니다.
3.4.1. GitOps, 그리고 SSOT(Single Source Of Truth)
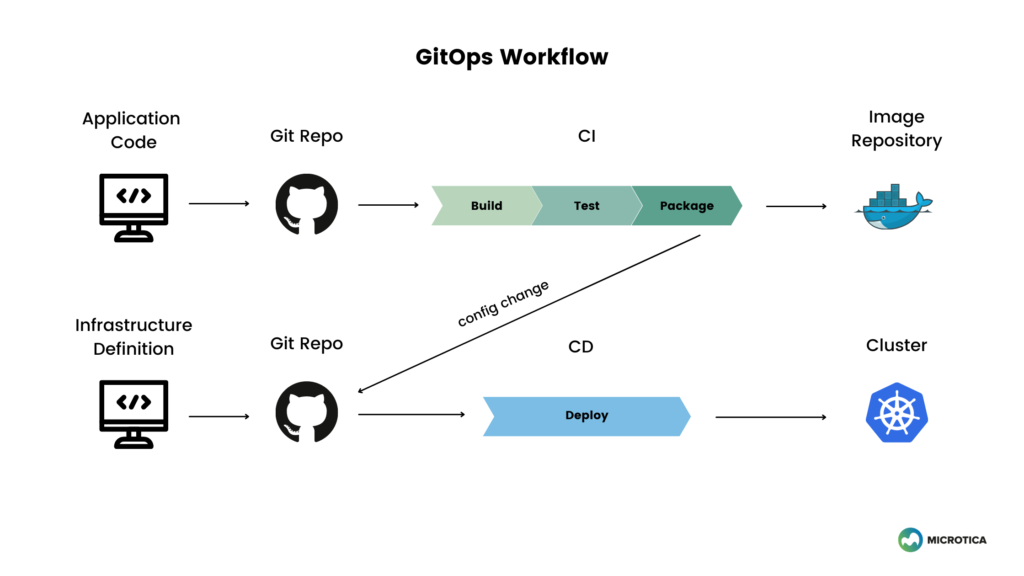
GitOps의 개념을 알아보겠습니다. 이전에 살펴본 Kubernetes의 코드 선언 방식과 앞서 설명드린 Helm의 설정 과정을 생각해 보면, Kubernetes의 모든 리소스는 코드로 정의할 수 있습니다.
이러한 방식으로 GitOps는 이 코드를 깃(Git) 저장소에 보관하고, 그 코드가 실제 운영 환경과 일치하도록 관리 및 운영(Ops)하는 방법론을 의미합니다.
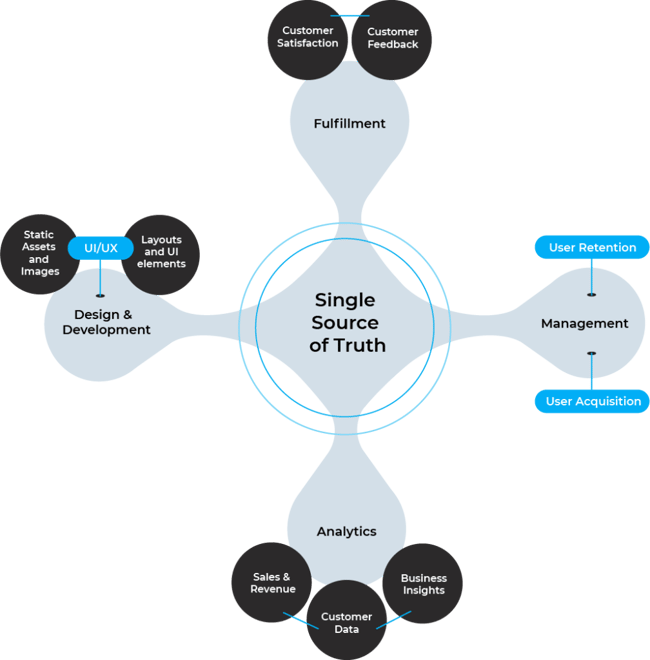
GitOps는 “SSOT (Single Source of Truth)”이라는 개념을 중심으로 운영됩니다. 이 개념을 조금 더 자세히 살펴보면, SSOT는 데이터 관리 원칙 중 하나로, 시스템 전반에 걸쳐 신뢰할 수 있고 정확한 하나의 데이터 버전만 존재해야 한다는 것을 의미합니다. 이 원칙은 시스템 운영의 일관성, 정확성, 효율성을 크게 향상시키는 역할을 합니다.
- 일관성 유지: SSOT는 데이터의 일관성을 보장하는 데 중요한 역할을 합니다. 여러 곳에서 동일한 데이터를 별도로 관리하지 않기 때문에 데이터 중복이나 불일치의 문제가 발생할 가능성이 낮아집니다.예를 들면, 고객 정보가 여러 시스템에 분산되어 있지 않고 하나의 시스템에서만 관리된다면, 어느 시스템에서나 항상 최신의 정확한 정보를 사용할 수 있게 됩니다.
- 정확성 보장: SSOT의 개념은 데이터의 정확성을 높일 수 있습니다. 하나의 소스에서만 데이터가 유지되고 업데이트 되므로, 데이터의 불일치나 충돌 가능성이 줄어들며, 모든 시스템이 동일한 정확한 데이터를 참조할 수 있습니다.
- 효율성 향상: 데이터를 관리할 단일 위치가 있으므로, 데이터의 업데이트나 유지 관리가 훨씬 효율적으로 이루어질 수 있습니다. 새로운 데이터를 추가하거나 기존 데이터를 수정할 때, 한 번의 작업으로 모든 시스템에 동일한 변경 사항이 반영될 수 있습니다.
GitOps는 모든 시스템과 사용자가 SSOT 원칙에 따라 동일한 데이터 소스를 참조하기 때문에 정보의 불일치 가능성이 줄어들며, 중복된 데이터를 관리하고 동기화하는 데 필요한 노력과 비용이 크게 감소합니다. 결과적으로, 전체 시스템의 운영 효율성이 향상되고 히스토리를 조회하는 기능이 자주 활용되며, 이를 통해 필요한 정보를 신속하게 검색할 수 있습니다.
GitOps를 구현할 수 있는 도구는 ArgoCD, Flux, Jenkins, Weaveworks, Spinnaker 등 여러가지가 있습니다. 저희 디스프레드 랩스는 이 중에서 사용하기가 가장 편리한 UI를 가지고 있고, 다른 도구와의 연동 편리성 그리고 풍부한 레퍼런스를 근거로 ArgoCD를 채택했습니다.
3.4.2. ArgoCD
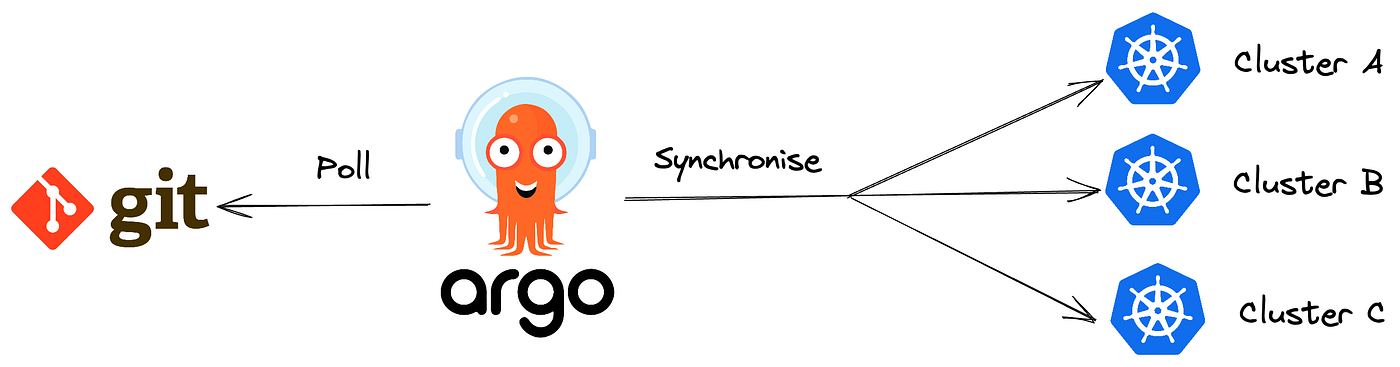
ArgoCD는 Kubernetes 환경에서 애플리케이션을 선언적으로 배포하고 관리할 수 있는 GitOps 도구입니다. Git 저장소에 정의된 애플리케이션 상태를 기준으로 Kubernetes 클러스터를 자동으로 동기화하며, 지속적인 배포(CD) 프로세스를 간소화 할 수 있습니다. 그리고 Git 저장소를 모니터링하여 변경 사항이 발생할 때 이를 Kubernetes 클러스터에 자동으로 반영하며, 이를 통해 인프라와 애플리케이션의 일관성을 유지합니다.
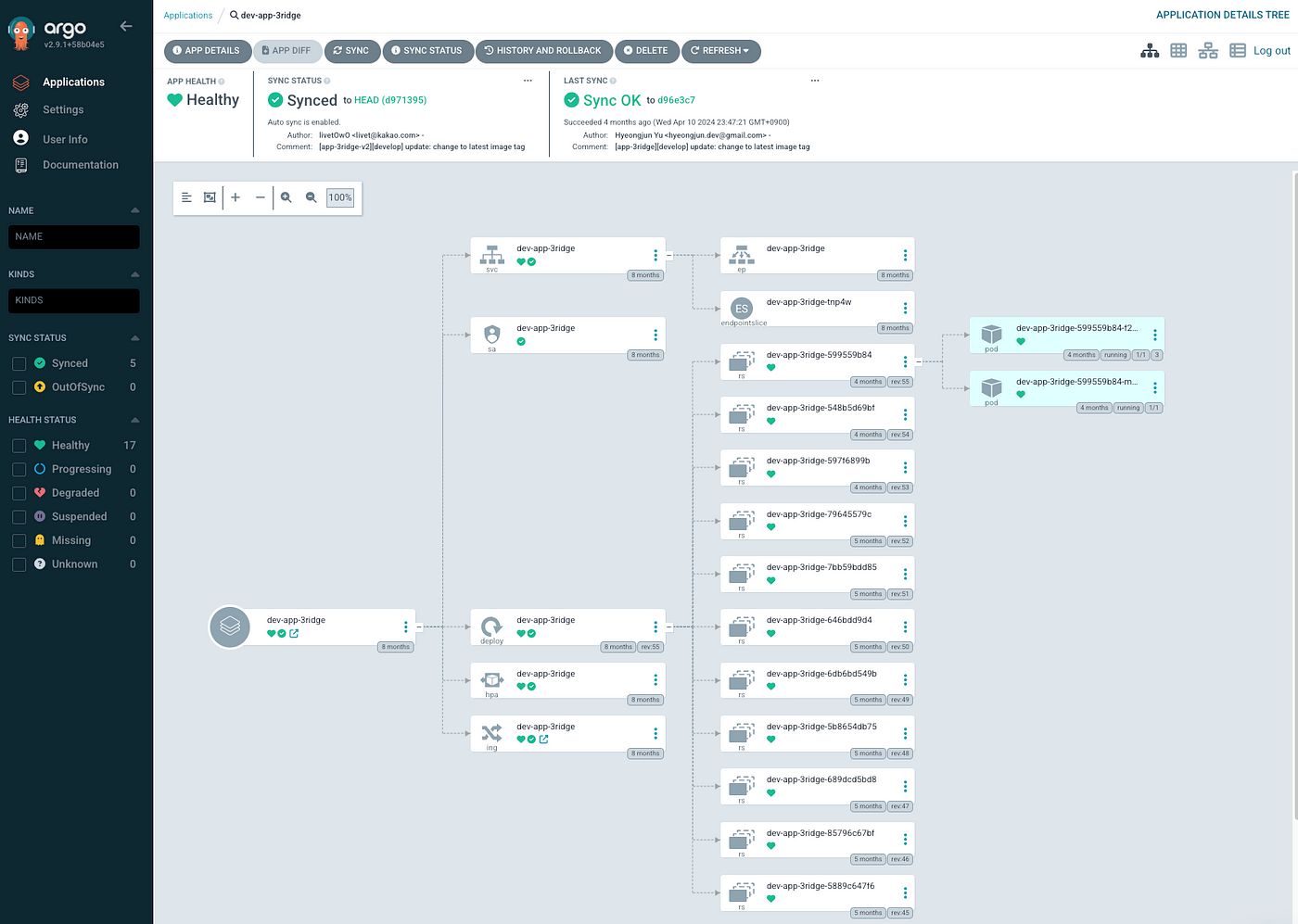
실시간 상태 모니터링과 관리 기능을 제공하여 사용자가 애플리케이션의 배포 상태를 쉽게 파악할 수 있습니다. 무엇보다 편리한 사용자 인터페이스(UI)를 통해 Kubernetes 리소스의 현재 상태와 Git 저장소의 선언적 정의 간의 차이를 시각적으로 확인할 수 있으며, 필요한 경우 롤백 및 롤아웃 작업도 간편하게 수행할 수 있습니다. 이를 활용해 디스프레드 랩스는 코드 변경 사항을 신속하게 배포하고, 문제 발생 시 빠르게 이전 상태로 복구할 수 있습니다.

멀티 클러스터 환경도 지원하며 사용자 인증, 권한 관리, RBAC(Role-Based Access Control) 등 보안 기능도 제공하기 때문에 엔터프라이즈 환경에서도 안정적으로 운영할 수 있습니다.
위 ArgoCD의 권한 관리 프로세스를 예로 들어보겠습니다.
- 사용자가 ArgoCD에서 새 계정을 생성하는 workspace 블록부터 시작하여 Config Map (*-cm.yaml)을 사용하여 Argo CD CLI를 통해 새 계정에 RBAC 규칙을 추가해 보겠습니다.
- workspace 블록에서 계정을 만들고 사용자 계정에 RBAC를 추가합니다.
- argocd namespace 블록은 사용자가 새 계정을 사용하여 작업을 수행할 때 RBAC가 작동하는 방식을 보여줍니다.
- 다이어그램에서 사용자는 새 계정을 사용하여 ArgoCD에서 애플리케이션을 삭제하려고 합니다.
- 계정에 애플리케이션을 삭제하는 RBAC 정책이 있는 경우 애플리케이션이 삭제 되고, 그렇지 않은 경우 사용자에게 권한에 대한 거부 메시지가 표시됩니다.
3.4.3. App of Apps

현재 Helm Chart를 ArgoCD를 통해 “App of Apps” 패턴으로 관리하고 있습니다. App of Apps 패턴은 대규모 Kubernetes 환경에서 여러 애플리케이션을 효과적으로 관리하기 위한 접근 방식입니다.
이 패턴은 ArgoCD를 사용하여 여러 Kubernetes 애플리케이션을 하나의 상위 애플리케이션(App)으로 구성하고, 그 상위 애플리케이션이 하위 애플리케이션들을 관리하는 구조를 의미합니다. 이러한 구조를 통해 복잡한 애플리케이션 배포를 보다 쉽게 관리하고 확장할 수 있습니다.
기본적으로, “App of Apps” 패턴에서는 하나의 ArgoCD 애플리케이션이 다른 ArgoCD 애플리케이션들을 참조하는 방식으로 동작합니다. 상위 애플리케이션은 여러 개의 하위 애플리케이션을 Git 저장소에 정의된 여러 애플리케이션 설정 파일들을 통해 관리합니다. 상위 애플리케이션이 각 하위 애플리케이션의 정의를 가져와 ArgoCD를 통해 Kubernetes 클러스터에 배포하거나 업데이트하게 됩니다.
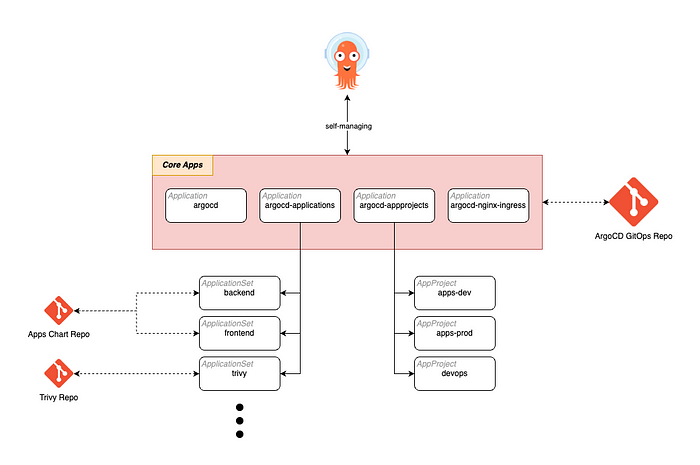
“App Of Apps” 패턴의 주요 장점은 관리의 간소화와 확장성입니다. 상위 애플리케이션을 통해 전체 시스템의 구성을 한 곳에서 중앙 집중식으로 관리할 수 있기 때문에, 새로운 하위 애플리케이션을 추가하거나 기존 애플리케이션을 변경할 때 전체 시스템에 대한 가시성과 제어를 유지할 수 있습니다. 또, 대규모 조직이나 팀에서 여러 애플리케이션을 동시에 관리하는 데 유용하며, 각 애플리케이션의 변경 사항이 체계적으로 반영되도록 도와줍니다.
예를 들어, 여러 팀이 각각의 마이크로서비스 애플리케이션을 독립적으로 개발하고 배포하는 환경에서 “App of Apps” 패턴을 사용하면, 각 팀은 자신들의 하위 애플리케이션을 관리할 수 있습니다. 그러면서도 상위 애플리케이션을 통해 전체 마이크로서비스의 상태를 일괄적으로 관리할 수 있어, 복잡한 배포 작업을 단순화하고 일관된 배포를 보장할 수 있습니다. 이는 특히 여러 환경(ex: 개발, 스테이징, 프로덕션)에서의 배포를 일관되게 유지하는 데 유리합니다.
4. 모니터링 및 알람 시스템
지금까지 디스프레드 랩스에서 Kubernetes를 도입할 때 사용한 도구와 적절한 배포 전략에 대해 설명했습니다. Kubernetes의 구축이 중요한 만큼, 구축 후 서비스의 안정성과 성능을 유지하는 것도 필수적입니다. 이를 위해서는 서비스에 대한 지속적인 모니터링과, 특정 조건에 따라 자동으로 동작하는 알람 시스템을 구축하는 것이 핵심입니다. 이러한 모니터링과 알람 시스템은 실제로 안정적인 서비스를 운영하는 데 있어 개발 및 운영팀이 반드시 갖추어야 할 요소로, 서비스의 가용성과 신뢰성을 보장하는 데 결정적인 역할을 합니다.
이러한 시스템이 잘 갖추어져 있으면, 예기치 않은 문제가 발생했을 때 빠르게 대응할 수 있으며, 사전에 위험을 감지하여 문제를 방지할 수 있습니다. 따라서 Kubernetes 도입 후에는 이와 같은 운영 관리 도구들을 잘 설정하고 최적화하는 것이 성공적인 운영의 중요한 열쇠라 할 수 있습니다.

Kubernetes를 모니터링하고 시스템 메트릭을 수집하는 여러 도구가 있지만, 저희 개발팀에서는 “PLG” 라고 통칭하는 Promtail + Loki + Grafana의 조합으로 모니터링 시스템을 구축했습니다.
4.1. PLG 스택
PLG Stack은 Promtail, Loki, Grafana의 약자로, 이들 도구를 조합하여 시스템 모니터링, 로깅, 시각화를 관리하는 데 사용되는 스택입니다. 각각의 역할은 다음과 같습니다.
- Promtail: Kubernetes 환경에 특화된 에이전트로서 Docker, FluentD 등 다른 로그 수집 에이전트도 사용 가능하며 데몬셋으로 실행되어 각 로그를 중앙 Loki 서버에 전달합니다.
- Loki: 로그 수집 및 분석 도구로, Prometheus와 유사한 방식으로 작동하며, Kubernetes 환경에서의 로그를 효율적으로 수집하고 검색할 수 있습니다.
- Grafana: Prometheus와 Loki에서 수집된 메트릭과 로그를 시각화하는 도구로, 대시보드와 경고 시스템을 통해 데이터를 쉽게 분석할 수 있도록 도와줍니다.
4.1.1. EFK vs PLG 중 어느 것이 적합한가?
Kubernetes를 모니터링 하는데 PLG 스택 외에도 EFK(Elastic search + Logstash + FluentD)가 방식도 있습니다. Kubernetes 환경에서 모니터링과 로그 관리를 위한 강력한 도구들입니다. 하지만 PLG 스택은 EFK에 비해 몇 가지 장점이 있습니다.
- 경량성과 효율성: Loki는 Elasticsearch보다 가벼우며, 로그를 인덱싱하지 않고 메타데이터를 통해 검색하므로 저장소와 자원 사용이 더 효율적입니다.
- 통합된 모니터링: Prometheus와 Loki는 동일한 쿼리 언어를 사용해 메트릭과 로그를 결합해 분석할 수 있으며, Grafana에서 이를 한 대시보드에서 시각화할 수 있어 일관된 관리가 가능합니다.
- 간편한 설치와 유지관리: PLG 스택은 설치와 운영이 상대적으로 간단하며, 클라우드 네이티브 환경에 최적화되어 Kubernetes와의 통합이 자연스럽습니다.
- 확장성: Loki는 스케일링이 용이하여 대규모 클러스터 환경에서도 유연하게 대응할 수 있습니다.
PLG 스택은 특히 경량성, 일관된 모니터링 경험, 클라우드 네이티브 환경에 최적화된 관리와 같은 장점을 제공하기 때문에 EFK 스택에 비해 리소스 효율적이고 간편하게 운영할 수 있습니다.
반면, EFK 스택은 대규모 데이터 분석 및 복잡한 쿼리 기능이 필요한 경우 여전히 유용할 수 있지만, 현재 규모에서는 오버 엔지니어링(Over Engineering)이라고 판단했습니다.
4.2. 모니터링 시스템
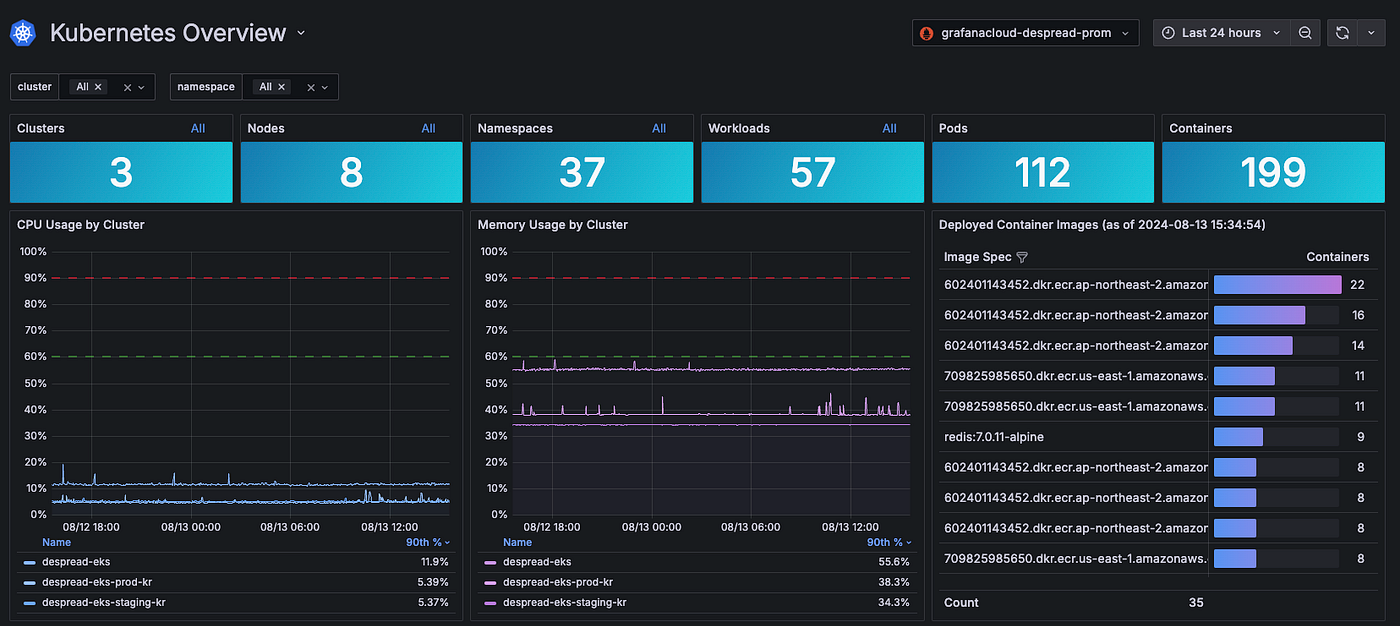
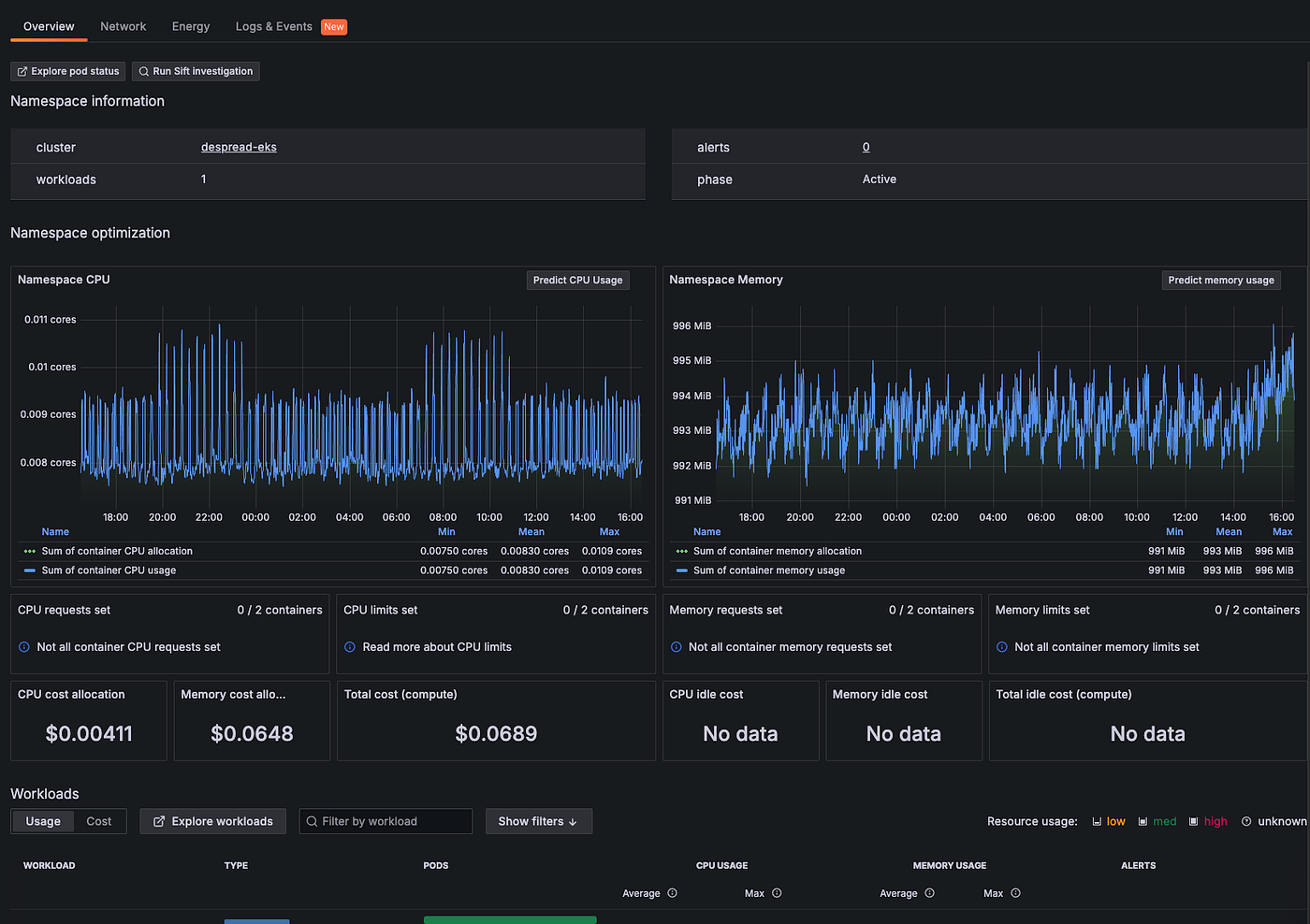
현재 디스프레드 랩스에서는 Grafana를 통해 위와 같이 Kubernetes의 현황을 모니터링하고 있습니다.
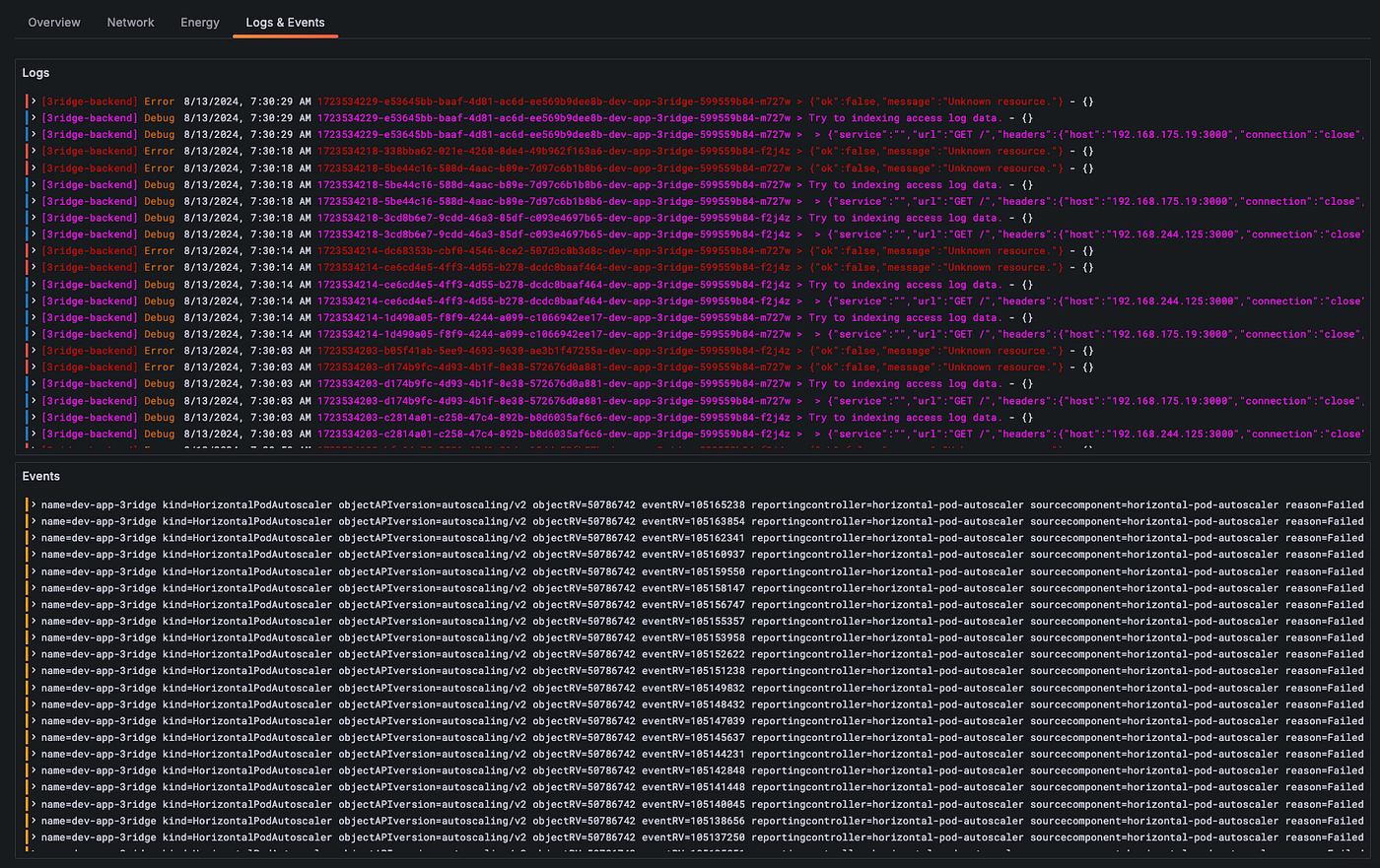
Grafana를 통해서 Kubernetes로 관리되는 Pod에 대한 로그 또한 Loki를 통해 수집 및 저장하여 모니터링 하고 있습니다.
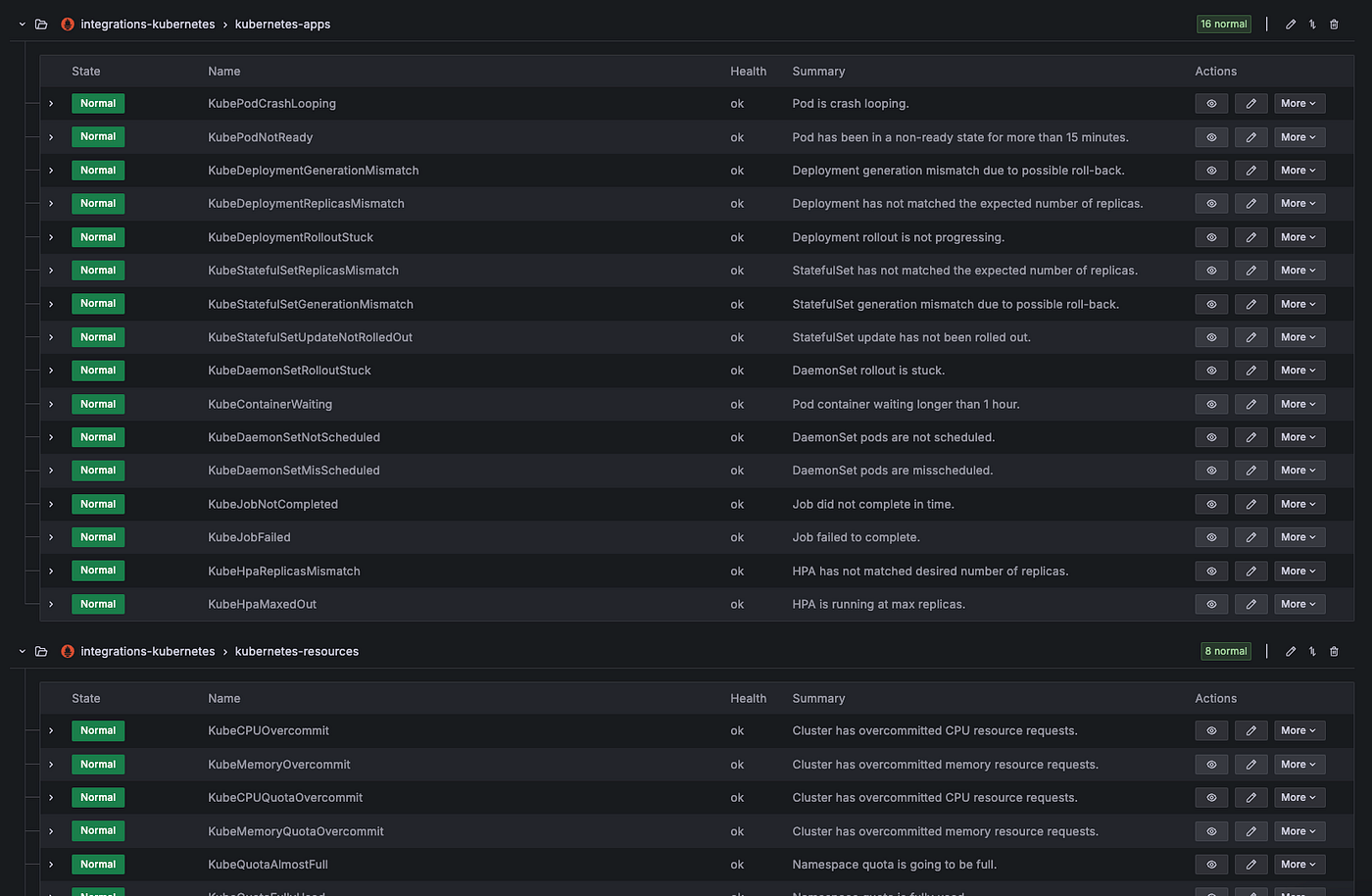
모니터링 뿐만 아니라, Kubernetes의 각 워커 노드별 시스템 지표 및 클러스터의 상태 등 어플리케이션 관련 지표 외에 Kubernetes와 관련된 50개 이상의 알람을 설정해두어, 안전한 서비스를 운영하고 있습니다.
4.3. 사고 관리 시스템
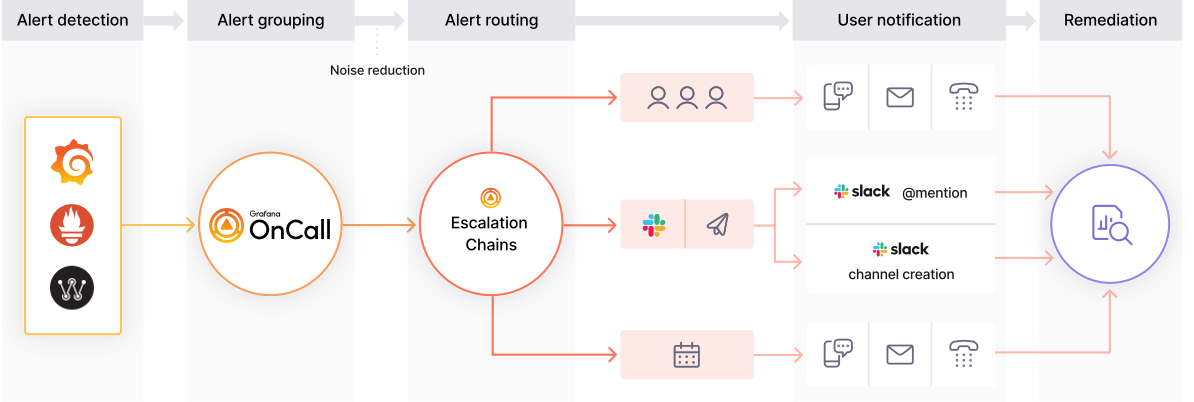
디스프레드 랩스에서는 Kubernetes 환경에서 PLG 스택을 활용하여 시스템 메트릭을 철저히 모니터링할 뿐만 아니라, 이를 기반으로 한 체계적인 사고 관리 프로세스를 운영하고 있습니다. 수집된 데이터를 통해 특정 시스템 메트릭이 사전에 정의된 임계치를 초과할 경우, Grafana On-Call을 통해 자동으로 알람이 발동되며, 단계별로 사고 관리가 진행됩니다.
- Slack을 통한 초기 알람: 첫 번째 단계로, 시스템 메트릭이 임계치를 넘어섰을 때 Grafana On-Call은 즉시 Slack 그룹 채널로 알람 메시지를 전송합니다. 이를 통해 모든 관련 팀원들이 실시간으로 문제를 인지하고, 초기 대응을 시작할 수 있습니다. Slack의 실시간 알림 기능 덕분에 팀원들은 문제를 신속하게 논의하고, 필요한 조치를 빠르게 취할 수 있습니다.
- 문자 메시지로의 긴급 알림 확대: 만약 Slack을 통해 전달된 알람 이후에도 문제가 해결되지 않거나 상황이 더 심각해지면, Grafana On-Call은 다음 단계로 설정된 규칙에 따라 관련 팀원들에게 문자 메시지를 발송합니다. 이 단계는 문제의 긴급성을 강조하며, Slack 알림을 놓친 팀원들이 상황을 빠르게 인지할 수 있도록 보완적인 역할을 합니다.
- 전화 알림을 통한 최종 대응: 문제가 여전히 해결되지 않으면, Grafana On-Call은 최종 단계로 전화 알림을 통해 팀원들에게 직접 사고를 통보합니다. 이 단계는 가장 심각한 상황을 대비한 조치로, 모든 팀원이 확실히 문제를 인지하고 즉각적인 대응을 할 수 있도록 보장합니다. 전화 알림은 상황의 긴급성을 최대한 강조하여, 즉각적인 액션을 유도합니다.
이와 같이, Kubernetes PLG 스택을 통해 수집된 데이터를 기반으로 체계적인 알람 및 사고 관리 시스템을 구축하였습니다. 단계별로 Slack, 문자 메시지, 전화 알림을 통해 문제가 해결될 때까지 적극적으로 대응할 수 있도록 하여, 서비스의 안정성을 유지하고 사고로 인한 영향을 최소화하고 있습니다.
5. 마치며
최근 디스프레드 랩스는 급격한 조직의 성장에 맞춰 Kubernetes를 도입하여 개발 및 운영 환경을 개선하는 등 현재도 현대화하는 작업을 지속적으로 진행하고 있습니다.
이를 통해 CI/CD 파이프라인을 효율적으로 관리하고, ArgoCD와 Helm Chart를 활용해 애플리케이션 배포를 간소화하며, 시스템의 유연성과 확장성을 확보했습니다. 또한, PLG 스택(Promtail, Loki, Grafana)을 통해 실시간 모니터링과 체계적인 사고 관리 시스템을 구축하여 서비스의 안정성과 신뢰성을 크게 향상시킬 수 있었습니다.
이러한 노력을 통해 개발 생산성을 높이고, 운영의 복잡성을 줄이며, 안정적인 서비스 제공을 위한 탄탄한 기반을 마련할 수 있었습니다. 조직의 빠른 성장에 발맞추거나 개발 생산성을 높이기 위해 Kubernetes 도입을 고민하는 다른 조직들에게 이 사례가 유용한 참고가 되기를 바라며, 글을 마칩니다.