
Journey to Kubernetes Adoption: Maximizing Growth and Efficiency
DeSpread Labs' Journey to Kubernetes Adoption

1. Introduction
DeSpread has spent the past five years collaborating with numerous Web3 companies, continually exploring ways to better support them and contribute to the market. As a result, starting last year, DeSpread began to formally establish DeSpread Labs, an internal development team. Recently, the team has nearly tripled in size.
In line with this growth, DeSpread Labs is undertaking various "modernization" efforts to enhance development efficiency. Existing projects are being migrated to Kubernetes, and all new projects are being developed on this platform from the outset. Throughout this process, the team has encountered numerous challenges and gained new insights.
We are in the process of migrating existing projects to Kubernetes, and all new projects are being developed based on Kubernetes. Throughout this journey, we have encountered many trials and errors and acquired new knowledge.
In this article, we will introduce the solutions DeSpread Labs has chosen and applied in the process of adopting Kubernetes, along with the journey and rationale behind these decisions.
2. Previous CI/CD Strategy

The diagram above illustrates our previous CI/CD strategy before adopting Kubernetes.
Managing infrastructure using the AWS console made it challenging to efficiently manage the various services we used.
Moreover, the build/deploy process after merging branches was cumbersome, and implementing various deployment strategies such as rolling updates, blue/green deployments, and canary deployments was complicated. In particular, it was difficult to perform zero-downtime deployments in the production environment without writing separate scripts or using tooling.
2.1. Challenges in Managing Existing Infrastructure
After initially developing the product and rapidly finding Product Market Fit (PMF) based on the MVP, the DeSpread Labs needed to focus on minimizing management points for infrastructure or tooling. Therefore, we considered how to centralize the currently fragmented infrastructure and manage it efficiently based on the following criteria:
- Minimize infrastructure management
- Seamlessly integrate with the existing development environment of team members
- Ensure good scalability
- Enable easy monitoring and logging
- Reduce boilerplate code
2.2. Recognizing the Need for Kubernetes Adoption
2.2.1. Segmentation into Specific Domains
Initially, the DeSpread Labs focused only on operating the necessary tooling or validators based on the situation. As a result, the functions of each domain became segmented and grew in size, leading to dependency issues and rising management and development costs.
A new requirement emerged to separate each domain to reduce development costs and satisfy all the organic data flows provided by the previous monolithic structure.
2.2.2. Real-time Event Collection
The DeSpread Labs analyzes issues discussed in the community or on-chain information for research purposes and provides tailored content to users who have participated in events on our onboarding platform.
To achieve this, we need to collect events and logs and analyze user situations through data analysis. Additionally, data generated from each domain should be organically linked so that it can be utilized in different domains.
2.2.3. Environment Support for Microservices
As the languages and frameworks used differed based on the characteristics and situations of each service, it was challenging to scale quickly in the previous monolithic infrastructure environment. Therefore, we needed to configure an environment that allows for rapid deployment and testing of different environments for each microservice using scalable solutions like Kubernetes.
As the development organization grew in size, new requirements as described above emerged. DeSpread Labs adopted Kubernetes, which has many references and proven stability, to break away from the previous monolithic structure and respond to flexible environments, and separated different domain services.
3. Kubernetes Adoption
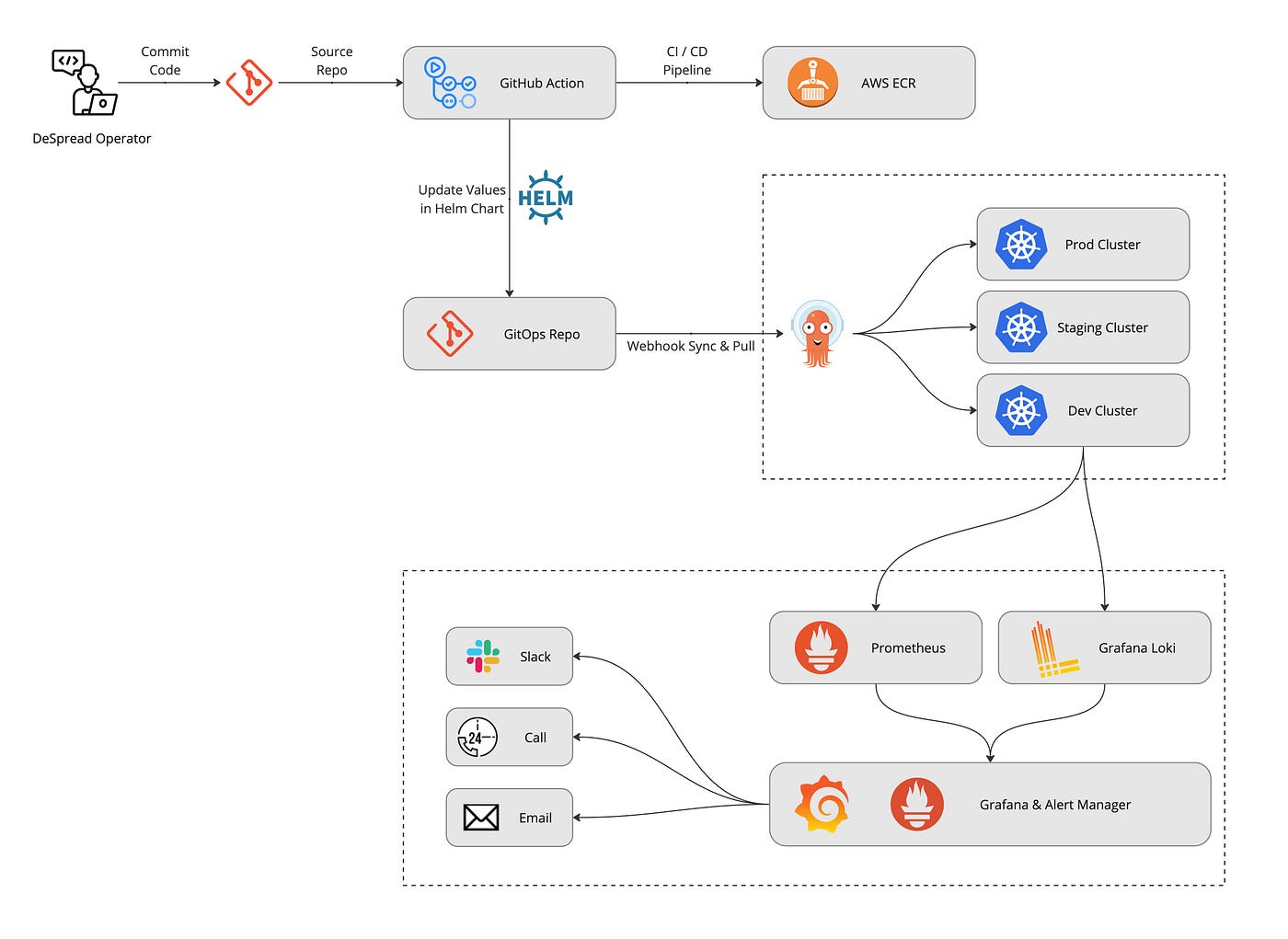
The image above shows the improved architecture after adopting Kubernetes. We have established development environments by dividing Kubernetes into three clusters: Production, Staging, and Dev.
Let's explore how the CI/CD process works.
3.1. CI (Continuous Integration)

CI is the concept of continuously integrating code while maintaining quality. At DeSpread Labs, we automated CI through GitHub Actions without any additional work when code is committed to a project's GitHub repository.
In the development environment, GitHub Actions are triggered when code is committed, while in the Staging and Prod environments, they are triggered when a Pull Request (PR) is merged. GitHub Actions build Docker images using Docker configuration files tailored to each project. Successfully built Docker images are uploaded to DeSpread Labs' private repository in AWS ECR (Elastic Container Registry).
Developers or stakeholders of a project can automatically execute builds and deployments without any additional work when making code changes, thereby increasing productivity.
3.2. CD (Continuous Delivery & Deployment)
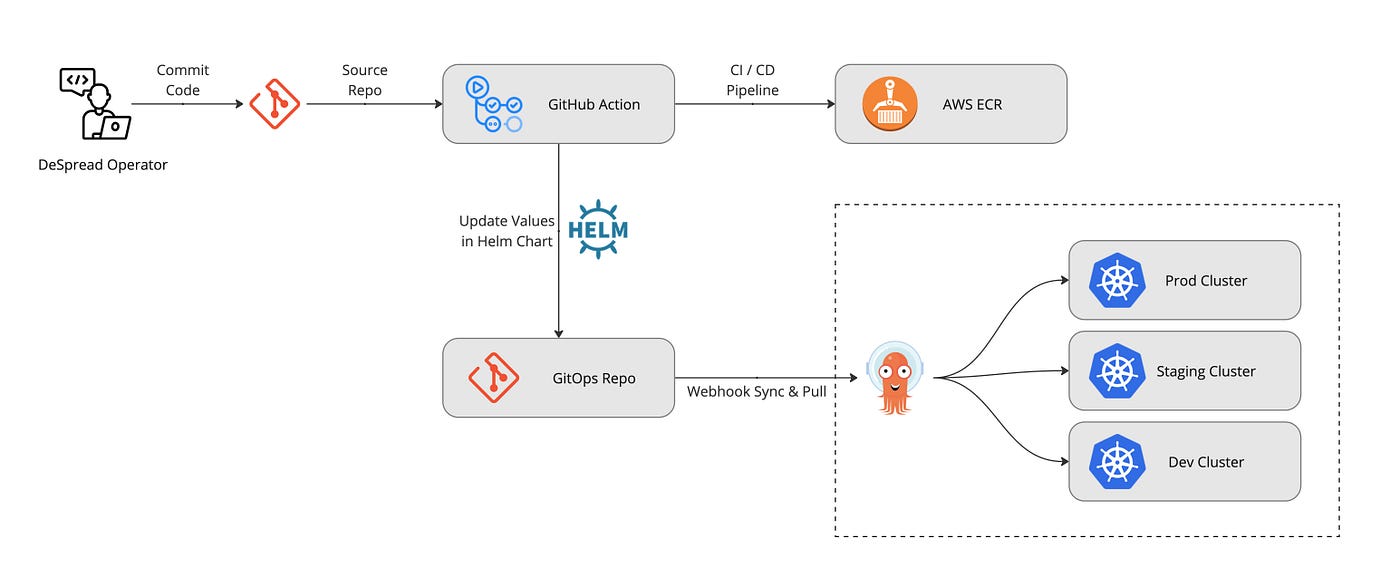
The GitHub Actions job triggered in the above CI process performs the final tasks for CD. The newly built Kubernetes is implemented based on Helm Charts following the App of Apps pattern.
It is fully separated by Production, Staging, and Development environments. Yaml files are managed together with project source code using Helm Charts. When code is merged according to branch operation procedures, it is automatically integrated through the above process and deployed to the Pod in the corresponding Kubernetes cluster. This entire process is carried out through ArgoCD, and operators can monitor it in real-time.
In case of failure, operators can roll back or change configurations through ArgoCD without the need to urgently modify Helm Chart configuration files in the GitHub Repository, making it easier to respond compared to before.
Moreover, based on the annotation settings of Service and Ingress, ALB (Application Load Balancer) is automatically created, and Route53 subdomain settings and ACM certificates are automatically linked to ALB. Now, developers only need to modify the code and merge it, and deployment is automated.
So far, we have provided an overview of the improved CI/CD process after adopting Kubernetes. Now, let's take a closer look at some of the key technologies used in this process.
3.3. Helm Chart
To build a Kubernetes environment using IaC (Infrastructure as Code), numerous Yaml configuration files need to be managed. Helm Chart is a tool for simplifying and automating the deployment and management of Kubernetes applications, offering features such as packaging, version control, deployment automation, reusability, dependency management, and standardization for complex applications.
This allows for maintaining consistent deployments across various environments, facilitating rollbacks and upgrades to specific versions, and enabling rapid application deployment by leveraging community-provided charts. DeSpread Labs chose Helm Chart as a package management tool for these reasons.
3.3.1. Helm Structure
Installing Helm and executing helm create {chartname} creates the following default structure:
├─ Chart.yaml
├─ charts
├─ templates
│ ├─ NOTES.txt
│ ├─ _helpers.tpl
│ ├─ deployment.yaml
│ ├─ hpa.yaml
│ ├─ service.yaml
│ ├─ serviceaccount.yaml
│ └─ tests
│ └─ tests-connection.yaml
└─ values.yaml
The Helm structure above can be briefly explained as follows:
- Chart.yaml: Specifies the name and version of the chart.
- Values.yaml: Contains modifiable configurations for the instance to be released.
- Templates: Contains template files that generate Kubernetes manifest files using variables declared in the values.yaml file.
- Charts: If dependent chart packages are specified in the requirement.yaml file, the chart files are stored in the charts folder.
3.4. Flexible Deployment Strategies
At DeSpread Labs, we manage Helm Charts through ArgoCD using the "App of Apps" pattern. Let's explore the concept of GitOps and how we manage code with appropriate strategies.
3.4.1. GitOps and SSOT (Single Source Of Truth)
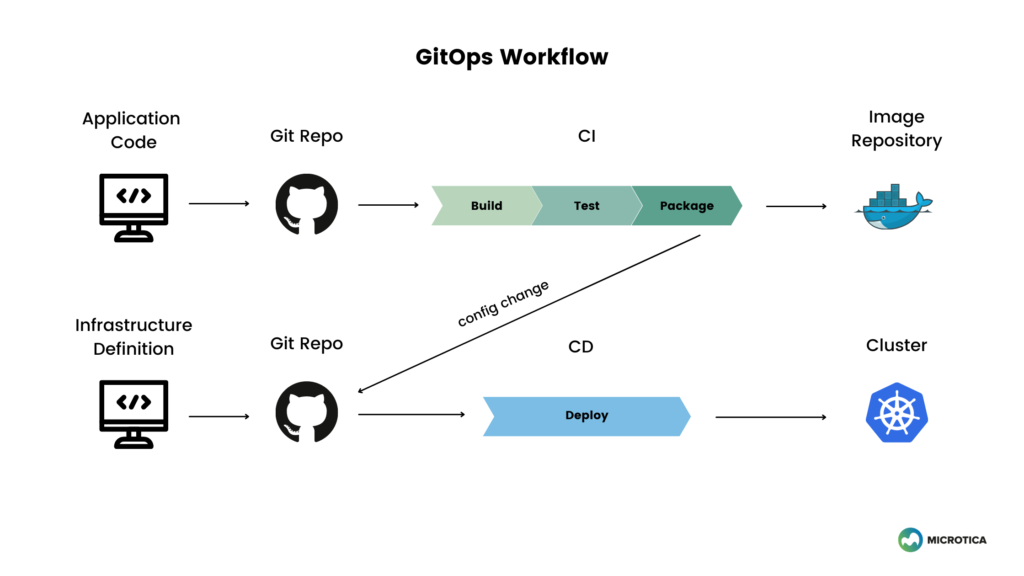
Let's explore the concept of GitOps. Considering the code declaration method of Kubernetes and the configuration process of Helm described earlier, all Kubernetes resources can be defined as code.
GitOps refers to the methodology of storing this code in a Git repository and managing and operating (Ops) it to ensure consistency between the code and the actual production environment.
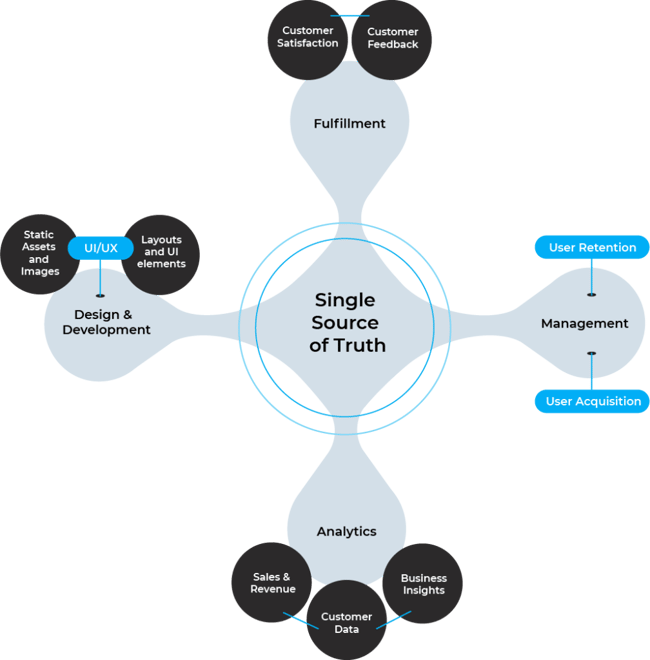
GitOps operates around the concept of "SSOT (Single Source of Truth)." Examining this concept further, SSOT is a data management principle that emphasizes the existence of a single, reliable, and accurate version of data throughout the system. This principle plays a crucial role in significantly improving the consistency, accuracy, and efficiency of system operations.
- Maintaining Consistency: SSOT plays a vital role in ensuring data consistency. Since the same data is not managed separately in multiple locations, the likelihood of data duplication or inconsistency is reduced. For example, if customer information is managed in a single system rather than being dispersed across multiple systems, accurate and up-to-date information can be used from any system.
- Ensuring Accuracy: The concept of SSOT can enhance data accuracy. As data is maintained and updated from a single source, the possibility of data inconsistency or conflicts is minimized, and all systems can reference the same accurate data.
- Improving Efficiency: With a single location to manage data, updates and maintenance can be performed much more efficiently. When adding new data or modifying existing data, a single operation can reflect the same changes across all systems.
GitOps reduces the possibility of information inconsistency and significantly decreases the effort and costs required to manage and synchronize duplicate data because all systems and users reference the same data source according to the SSOT principle. As a result, the overall operational efficiency of the system is enhanced, and the history lookup feature is frequently utilized, enabling quick retrieval of necessary information.
There are various tools available for implementing GitOps, such as ArgoCD, Flux, Jenkins, Weaveworks, and Spinnaker. The DeSpread Labs chose ArgoCD based on its user-friendly UI, ease of integration with other tools, and abundant references.
3.4.2. ArgoCD
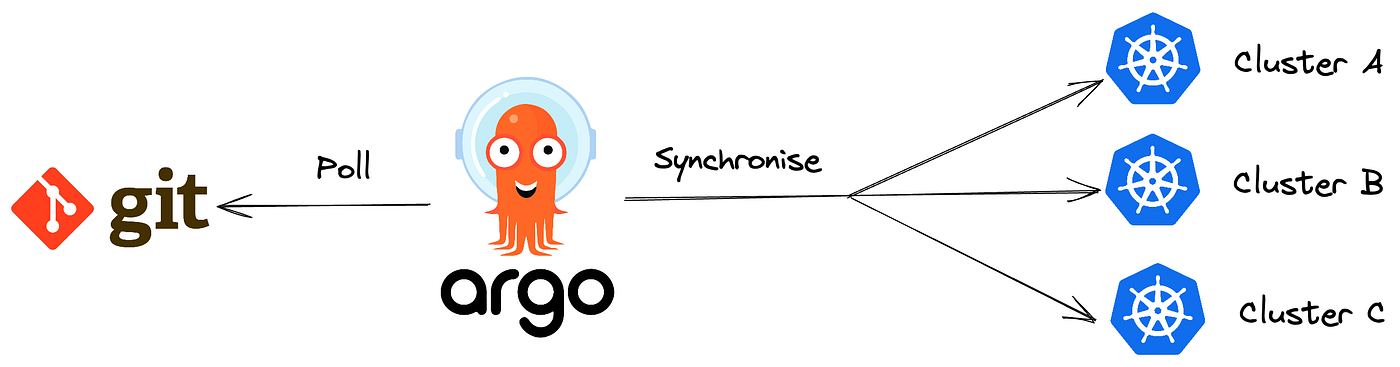
ArgoCD is a GitOps tool that enables declarative deployment and management of applications in Kubernetes environments. It automatically synchronizes the Kubernetes cluster based on the application state defined in a Git repository, simplifying the continuous deployment (CD) process. It monitors the Git repository and automatically reflects changes to the Kubernetes cluster when they occur, maintaining consistency between the infrastructure and applications.
ArgoCD provides real-time status monitoring and management capabilities, allowing users to easily understand the deployment status of applications. It offers a convenient user interface (UI) to visually identify differences between the current state of Kubernetes resources and the declarative definitions in the Git repository. It also enables simple rollback and rollout operations when needed. Using this, the DeSpread Labs can quickly deploy code changes and easily restore to the previous state in case of issues.

ArgoCD also supports multi-cluster environments and provides security features such as user authentication, permission management, and RBAC (Role-Based Access Control), making it suitable for stable operation in enterprise environments.
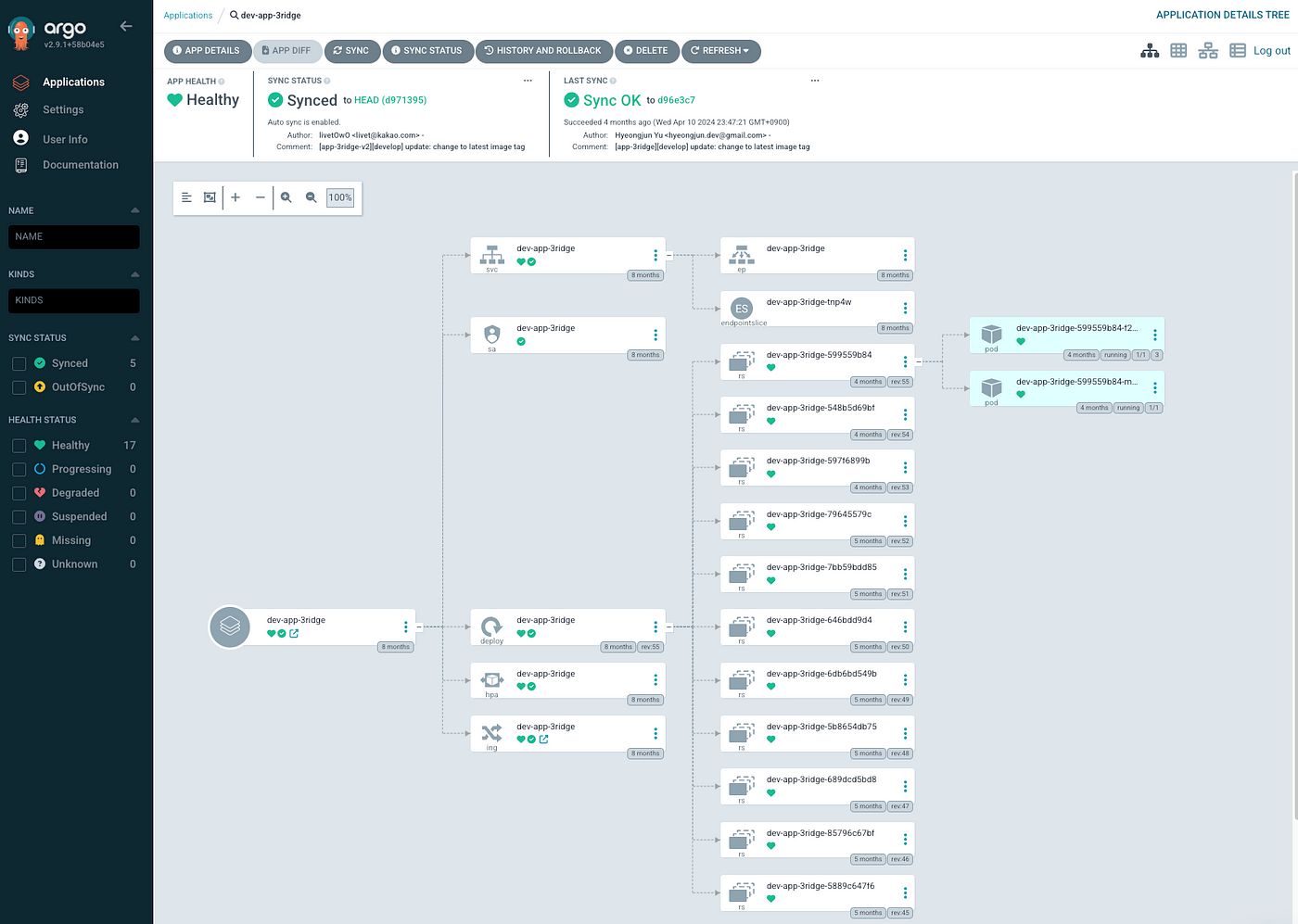
Let's take the ArgoCD permission management process shown above as an example.
- Starting from the workspace block where the user creates a new account, we'll add RBAC rules to the new account using the Config Map (*-cm.yaml) through the Argo CD CLI.
- In the workspace block, the account is created, and RBAC is added to the user account.
- The argocd namespace block shows how RBAC works when the user performs actions using the new account.
- In the diagram, the user tries to delete an application in ArgoCD using the new account.
- If the account has an RBAC policy to delete the application, the application is deleted; otherwise, a denial message regarding permissions is displayed to the user.
3.4.3. App of Apps

We manage Helm Charts through ArgoCD using the "App of Apps" pattern. The App of Apps pattern is an approach for effectively managing multiple applications in large-scale Kubernetes environments.
This pattern refers to the structure where ArgoCD is used to compose multiple Kubernetes applications into a single parent application (App), and that parent application manages the child applications. This structure allows for easier management and scaling of complex application deployments.
Fundamentally, in the "App of Apps" pattern, one ArgoCD application references other ArgoCD applications. The parent application manages multiple child applications through multiple application configuration files defined in a Git repository. The parent application retrieves the definitions of each child application and deploys or updates them to the Kubernetes cluster through ArgoCD.
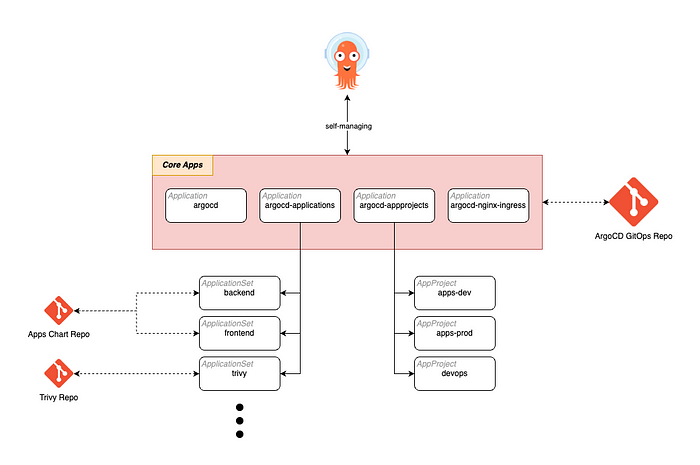
The main benefits of the "App of Apps" pattern are simplified management and scalability. By centrally managing the configuration of the entire system through the parent application, visibility and control can be maintained when adding new child applications or changing existing ones. It is also useful for managing multiple applications simultaneously in large organizations or teams, helping to systematically reflect changes in each application.
For example, in an environment where multiple teams independently develop and deploy their own microservice applications, using the "App of Apps" pattern allows each team to manage their own child applications. At the same time, the overall state of the microservices can be collectively managed through the parent application, simplifying complex deployment tasks and ensuring consistent deployments. This is particularly advantageous for maintaining consistent deployments across multiple environments (e.g., development, staging, production).
4. Monitoring and Alarm System
We have explained the tools used by DeSpread Labs when adopting Kubernetes and the appropriate deployment strategies. Just as important as building Kubernetes is maintaining the stability and performance of services after deployment. The key to this is establishing continuous monitoring of services and an alarm system that automatically operates based on specific conditions. These monitoring and alarm systems are essential elements that development and operations teams must have to ensure stable service operation, playing a crucial role in guaranteeing service availability and reliability.
With a well-established system, it is possible to quickly respond to unexpected issues and detect risks in advance to prevent problems. Therefore, after adopting Kubernetes, setting up and optimizing these operational management tools is a key to successful operations.

Although there are several tools for monitoring Kubernetes and collecting system metrics, our development team has built a monitoring system using the combination of Promtail + Loki + Grafana, collectively referred to as the "PLG" stack.
4.1. PLG Stack
PLG Stack is an abbreviation for Promtail, Loki, and Grafana, and this stack is used to manage system monitoring, logging, and visualization by combining these tools. Their roles are as follows:
- Promtail: A specialized agent for Kubernetes environments that can also use other log collection agents such as Docker and FluentD. It runs as a DaemonSet and forwards each log to the central Loki server.
- Loki: A log collection and analysis tool that operates similarly to Prometheus, efficiently collecting and searching logs in Kubernetes environments.
- Grafana: A tool for visualizing metrics and logs collected by Prometheus and Loki, helping to easily analyze data through dashboards and alert systems.
4.1.1. Which is more suitable, EFK or PLG?
In addition to the PLG stack, there is also the EFK (Elasticsearch + Logstash + FluentD) approach for monitoring Kubernetes. Both are powerful tools for monitoring and log management in Kubernetes environments. However, the PLG stack has several advantages over EFK.
- Lightweight and Efficient: Loki is lighter than Elasticsearch and searches through metadata without indexing logs, making storage and resource usage more efficient.
- Integrated Monitoring: Prometheus and Loki use the same query language to combine and analyze metrics and logs, and Grafana can visualize this on a single dashboard, enabling consistent management.
- Easy Installation and Maintenance: The PLG stack is relatively simple to install and operate, optimized for cloud-native environments, and naturally integrates with Kubernetes.
- Scalability: Loki is easily scalable and can flexibly adapt to large-scale cluster environments.
The PLG stack is particularly advantageous in terms of lightweight, consistent monitoring experience, optimized management for cloud-native environments, allowing for more efficient operation with fewer resources compared to the EFK stack.
On the other hand, the EFK stack can still be useful when large-scale data analysis and complex query capabilities are required, but we determined that it would be over-engineering for current scale.
4.2. Monitoring System
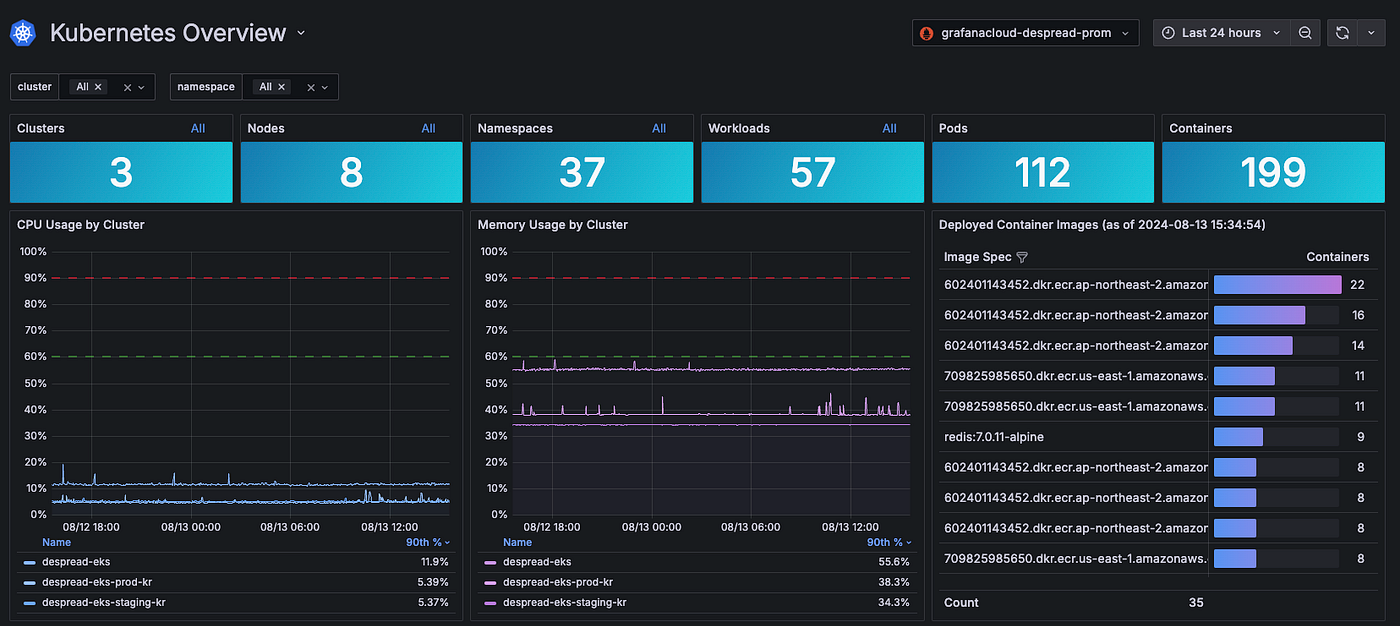
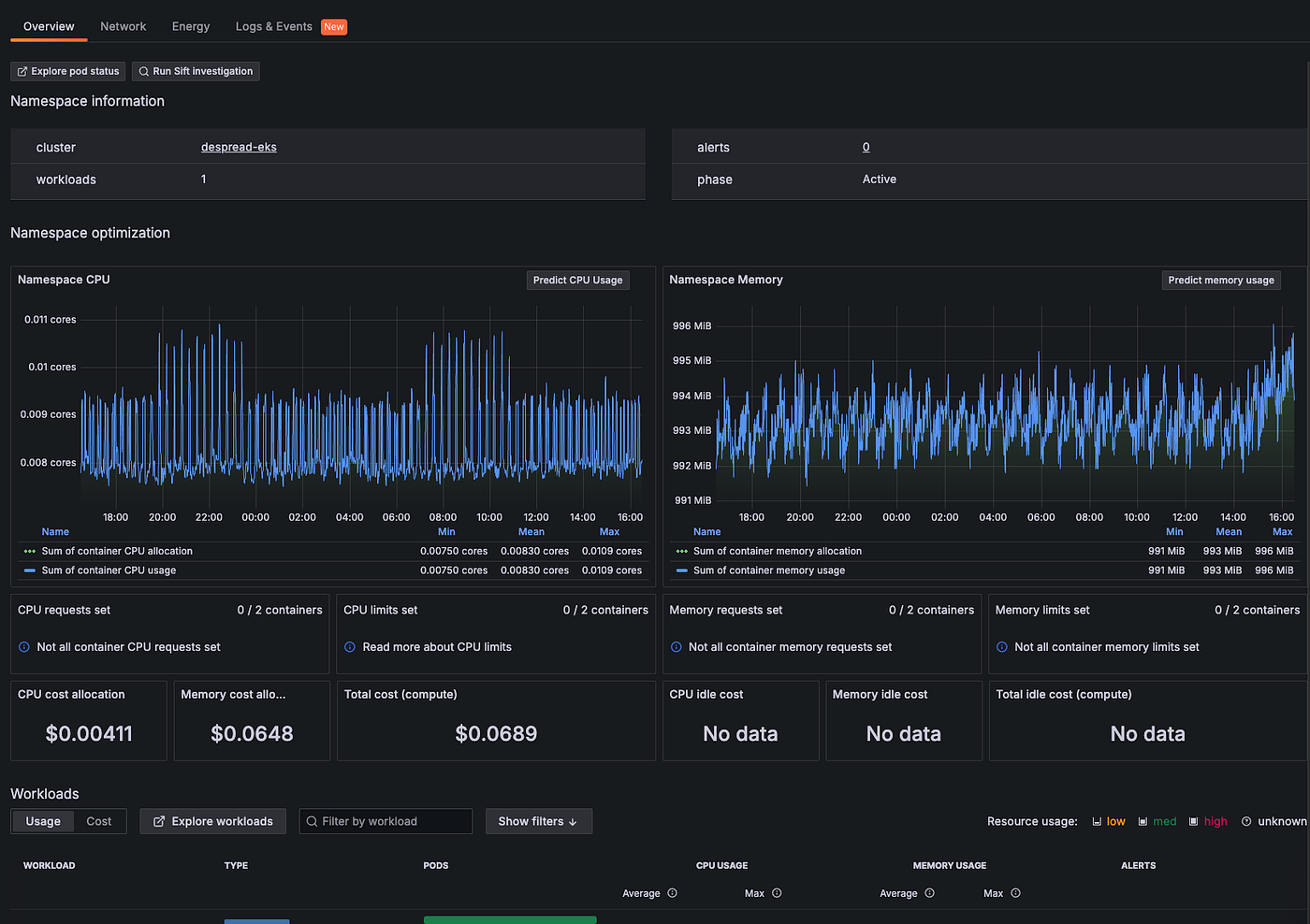
Currently, DeSpread Labs monitors the status of Kubernetes as shown above through Grafana.
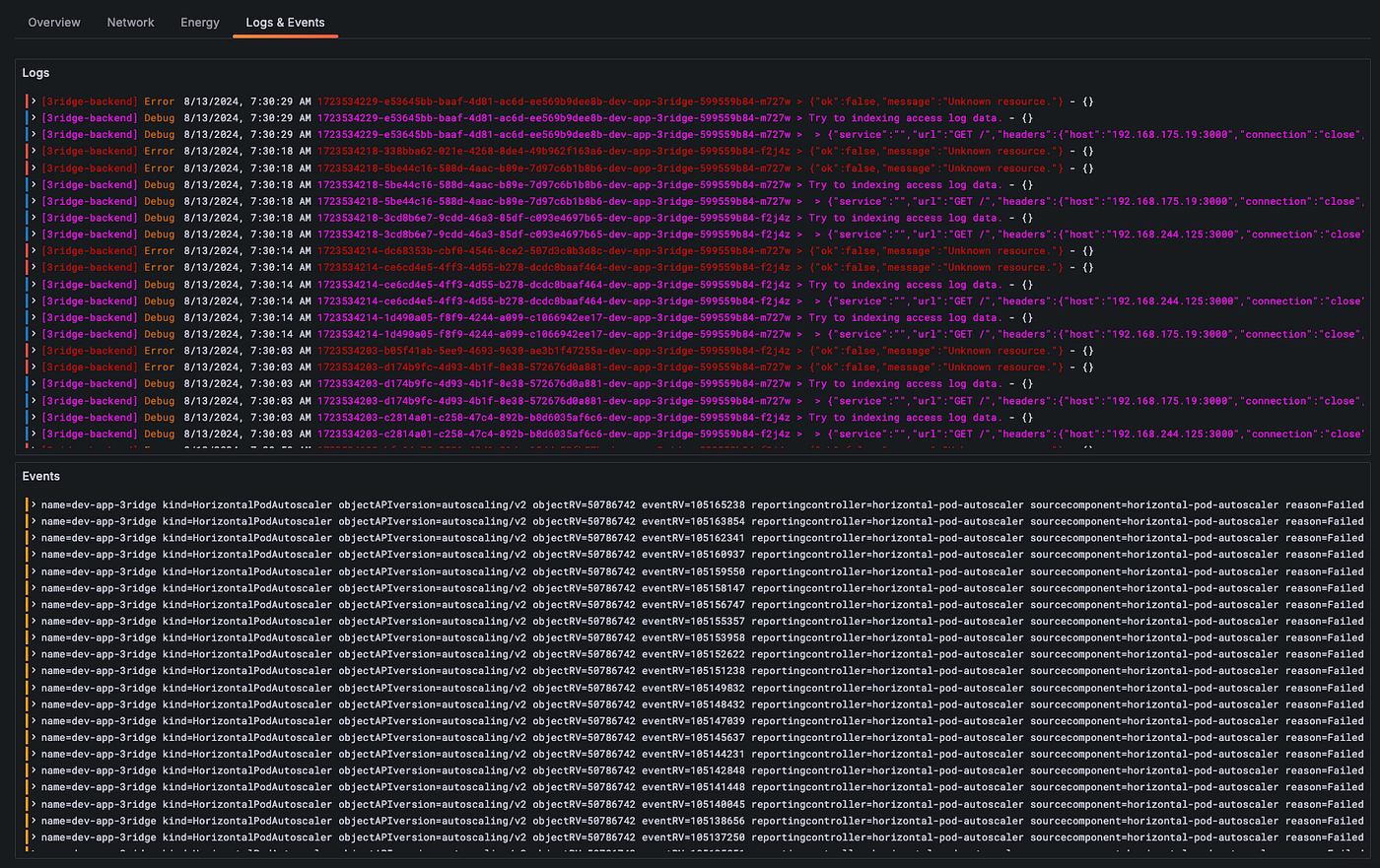
Through Grafana, logs for Pods managed by Kubernetes are also collected and stored via Loki for monitoring.
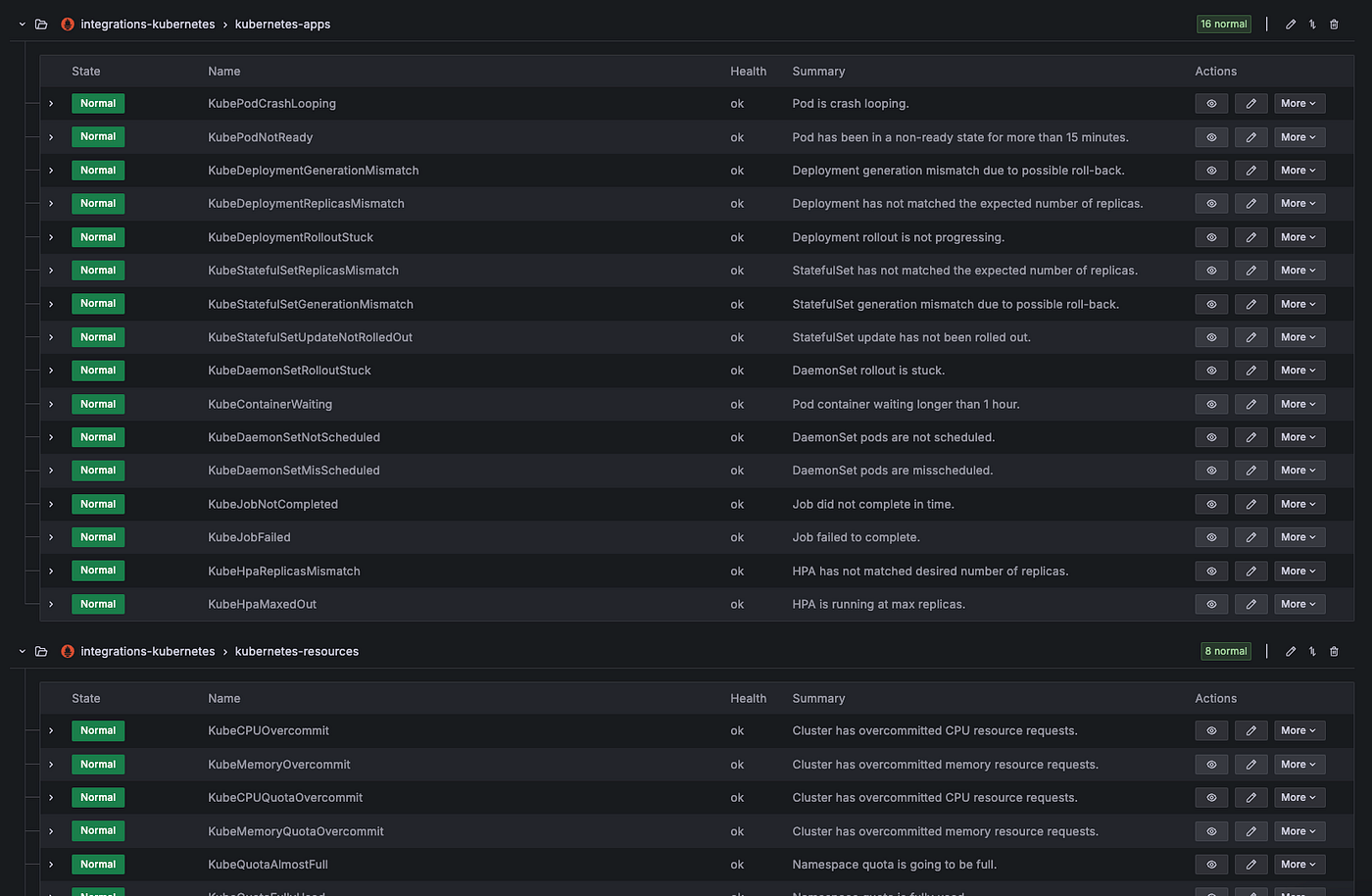
In addition to monitoring, more than 50 alarms related to Kubernetes, such as system metrics for each worker node and cluster status, are set up to ensure safe service operation.
4.3. Incident Management System
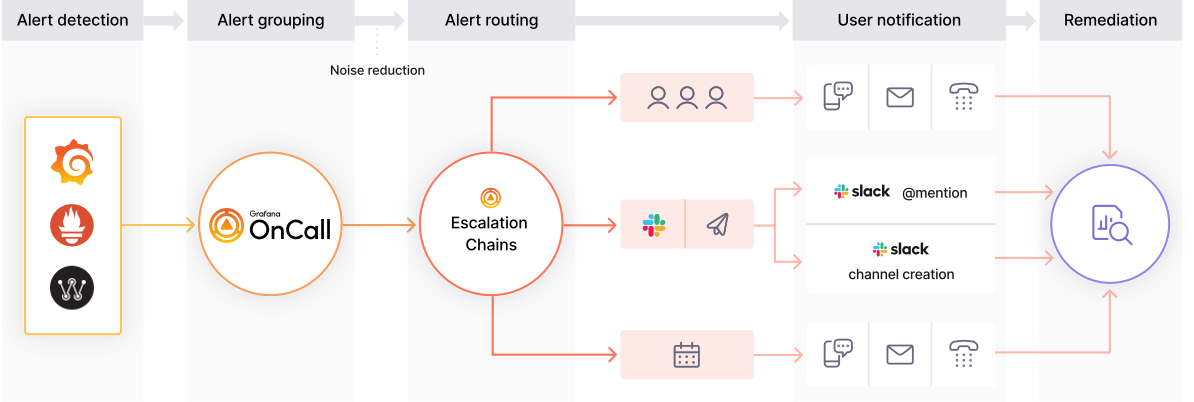
In the Kubernetes environment, DeSpread Labs not only thoroughly monitors system metrics using the PLG stack but also operates a systematic incident management process based on it. When specific system metrics exceed predefined thresholds based on the collected data, Grafana On-Call automatically triggers alarms, and incident management proceeds in stages.
- Initial Alarm via Slack: In the first stage, when system metrics exceed thresholds, Grafana On-Call immediately sends an alarm message to the Slack group channel. This allows all relevant team members to recognize the issue in real-time and initiate initial responses. Thanks to Slack's real-time notification feature, team members can quickly discuss the issue and take necessary actions.
- Escalation to SMS Alerts: If the issue is not resolved or the situation worsens after the alarm delivered via Slack, Grafana On-Call sends text messages to relevant team members according to the rules set for the next stage. This stage emphasizes the urgency of the issue and serves as a complementary role to ensure that team members who missed the Slack notification can quickly become aware of the situation.
- Final Response via Phone Alerts: If the issue remains unresolved, Grafana On-Call directly notifies team members of the incident through phone alerts as the final stage. This stage is a measure for the most severe situations, ensuring that all team members are aware of the issue and can take immediate action. Phone alerts maximize the emphasis on the urgency of the situation, prompting immediate action.
In this way, DeSpread Labs has established a systematic alarm and incident management system based on data collected through the Kubernetes PLG stack. By actively responding until the issue is resolved through staged Slack, text message, and phone alerts, service stability is maintained, and the impact of incidents is minimized.
5. Conclusion
Recently, DeSpread Labs has been continuously modernizing its environment, such as adopting Kubernetes and improving development and operation environments to keep pace with the rapid growth of the organization.
Through this, we have efficiently managed the CI/CD pipeline, simplified application deployment using ArgoCD and Helm Charts, and secured system flexibility and scalability. Additionally, by establishing real-time monitoring and a systematic incident management system through the PLG stack (Promtail, Loki, Grafana), we have significantly enhanced service stability and reliability.
These efforts have allowed our team to increase development productivity, reduce operational complexity, and establish a solid foundation for providing stable services. We hope that this case study serves as a useful reference for other organizations considering adopting Kubernetes to keep up with rapid organizational growth or to improve development productivity. With that, we conclude this article.